One of Linux’s keys to success is its ability to coexist comfortably with other systems. You can transparently mount disks or partitions that host file formats used by Windows, other Unix systems, or even systems with tiny market shares like the Amiga. Linux manages to support multiple filesystem types in the same way other Unix variants do, through a concept called the Virtual Filesystem.
The idea behind the Virtual Filesystem is to put a wide range of information in the kernel to represent many different types of filesystems; there is a field or function to support each operation provided by all real filesystems supported by Linux. For each read, write, or other function called, the kernel substitutes the actual function that supports a native Linux filesystem, the NTFS filesystem, or whatever other filesystem the file is on.
The Role of the Virtual Filesystem (VFS)
The VFS is an abstraction layer between the application program and the filesystem implementations.
The Virtual Filesystem (also known as Virtual Filesystem Switch or VFS) is a kernel software layer that handles all system calls related to a standard Unix filesystem. Its main strength is providing a common interface to several kinds of filesystems.
Filesystems supported by the VFS may be grouped into three main classes:
- Disk-based filesystems. These manage memory space available in a local disk or in some other device that emulates a disk (such as a USB flash drive).
- Network filesystems. These allow easy access to files included in filesystems belonging to other networked computers. Some well-known network filesystems supported by the VFS are NFS , Coda , AFS (Andrew filesystem), CIFS (Common Internet File System, used in Microsoft Windows ), and NCP (Novell’s NetWare Core Protocol).
- Special filesystems. These do not manage disk space, either locally or remotely. The /proc filesystem is a typical example of a special filesystem.
Unix directories build a tree whose root is the / directory. The root directory is contained in the root filesystem, which in Linux, is usually of type Ext2 or Ext3. All other filesystems can be “mounted” on subdirectories of the root filesystem.
When a filesystem is mounted on a directory, the contents of the directory in the parent filesystem are no longer accessible, because every pathname, including the mount point, will refer to the mounted filesystem. However, the original directory’s content shows up again when the filesystem is unmounted. This somewhat surprising feature of Unix filesystems is used by system administrators to hide files; they simply mount a filesystem on the directory containing the files to be hidden.
The key idea behind the VFS consists of introducing a common file model capable of representing all supported filesystems. This model strictly mirrors the file model provided by the traditional Unix filesystem. This is not surprising, because Linux wants to run its native filesystem with minimum overhead. However, each specific filesystem implementation must translate its physical organization into the VFS’s common file model.
- The superblock object. Stores information concerning a mounted filesystem. For disk-based filesystems, this object usually corresponds to a filesystem control block stored on disk.
- The inode object. Stores general information about a specific file. For disk-based filesystems, this object usually corresponds to a file control block stored on disk. Each inode object is associated with an inode number, which uniquely identifies the file within the filesystem.
- The file object. Stores information about the interaction between an open file and a process. This information exists only in kernel memory during the period when a process has the file open.
- The dentry object Stores. information about the linking of a directory entry (that is, a particular name of the file) with the corresponding file. Each disk-based filesystem stores this information in its own particular way on disk.
Figure 12-2 illustrates with a simple example how processes interact with files. Three different processes have opened the same file, two of them using the same hard link. In this case, each of the three processes uses its own file object, while only two dentry objects are require done for each hard link. Both dentry objects refer to the same inode object, which identifies the superblock object and, together with the latter, the common disk file.

Besides providing a common interface to all filesystem implementations, the VFS has another important role related to system performance. The most recently used dentry objects are contained in a disk cache named the dentry cache , which speeds up the translation from a file pathname to the inode of the last pathname component. Generally speaking, a disk cache is a software mechanism that allows the kernel to keep in RAM some information that is normally stored on a disk, so that further accesses to that data can be quickly satisfied without a slow access to the disk itself.
Notice how a disk cache differs from a hardware cache or a memory cache, neither of which has anything to do with disks or other devices. A hardware cache is a fast static RAM that speeds up requests directed to the slower dynamic RAM. A memory cache is a software mechanism introduced to bypass the Kernel Memory Allocator (like the Slab Allocator).
VFS Data Structures
The following declarations are located at ./include/linux/fs.h
Superblock Objects
All superblock objects are linked in a circular doubly linked list. The first element of this list is represented by the super_blocks variable, while the s_list field of the superblock object stores the pointers to the adjacent elements in the list.
The s_fs_info field points to superblock information that belongs to a specific filesystem; for instance, if the superblock object refers to an Ext2 filesystem, the field points to an ext2_sb_info structure, which includes the disk allocation bit masks and other data of no concern to the VFS common file model.
In general, data pointed to by the s_fs_info field is information from the disk duplicated in memory for reasons of efficiency. Each disk-based filesystem needs to access and update its allocation bitmaps in order to allocate or release disk blocks. The VFS allows these filesystems to act directly on the s_fs_info field of the superblock in memory without accessing the disk. This approach leads to a new problem, however: the VFS superblock might end up no longer synchronized with the corresponding superblock on disk. It is thus necessary to introduce an s_dirt flag, which specifies whether the superblock is dirty. That is, whether the data on the disk must be updated. The lack of synchronization leads to the familiar problem of a corrupted filesystem when a site’s power goes down without giving the user the chance to shut down a system cleanly. Linux minimizes this problem by periodically copying all dirty superblocks to disk.
Inode Objects
All information needed by the filesystem to handle a file is included in a data structure called an inode. A filename is a casually assigned label that can be changed, but the inode is unique to the file and remains the same as long as the file exists.
Each inode object duplicates some of the data included in the disk inode. For instance, the number of blocks allocated to the file. When the value of the i_state field is equal to I_DIRTY_SYNC, I_DIRTY_DATASYNC, or I_DIRTY_PAGES, the inode is dirty. That is, the corresponding disk inode must be updated. The I_DIRTY macro can be used to check the value of these three flags at once.
Each inode object always appears in one of the following circular doubly linked lists (in all cases, the pointers to the adjacent elements are stored in the i_list field):
- The list of valid unused inodes, typically those mirroring valid disk inodes and not currently used by any process. These inodes are not dirty and their i_count field is set to 0. The first and last elements of this list are referenced by the next and prev fields, respectively, of the inode_unused variable. This list acts as a disk cache.
- The list of in-use inodes, that is, those mirroring valid disk inodes and used by some process. These inodes are not dirty and their i_count field is positive. The first and last elements are referenced by the inode_in_use variable.
- The list of dirty inodes. The first and last elements are referenced by the s_dirty field of the corresponding superblock object.
Moreover, each inode object is also included in a per-filesystem doubly linked circular list headed at the s_inodes field of the superblock object; the i_sb_list field of the inode object stores the pointers for the adjacent elements in this list. Finally, the inode objects are also included in a hash table named inode_hashtable. The hash table speeds up the search of the inode object when the kernel knows both the inode number and the address of the superblock object corresponding to the filesystem that includes the file. Because hashing may induce collisions, the inode object includes an i_hash field that contains a backward and a forward pointer to other inodes that hash to the same position; this field creates a doubly linked list of those inodes.
File Objects
A file object describes how a process interacts with a file it has opened. The object is created when the file is opened and consists of a file structure. Notice that file objects have no corresponding image on disk, and hence no “dirty” field is included in the file structure to specify that the file object has been modified.
The main information stored in a file object is the file pointer the current position in the file from which the next operation will take place. Because several processes may access the same file concurrently, the file pointer must be kept in the file object rather than the inode object.
dentry Objects
The VFS considers each directory a file that contains a list of files and other directories. Once a directory entry is read into memory, however, it is transformed by the VFS into a dentry object based on the dentry structure. The kernel creates a dentry object for every component of a pathname that a process looks up; the dentry object associates the component to its corresponding inode. For example, when looking up the /tmp/test pathname, the kernel creates a dentry object for the / root directory, a second dentry object for the tmp entry of the root directory, and a third dentry object for the test entry of the /tmp directory.
Notice that dentry objects have no corresponding image on disk, and hence no field is included in the dentry structure to specify that the object has been modified. Dentry objects are stored in a slab allocator cache whose descriptor is dentry_cache; dentry objects are thus created and destroyed by invoking kmem_cache_alloc( ) and kmem_cache_free( ).
Because reading a directory entry from disk and constructing the corresponding dentry object requires considerable time, it makes sense to keep in memory dentry objects that you’ve finished with but might need later. For instance, people often edit a file and then compile it, or edit and print it, or copy it and then edit the copy. In such cases, the same file needs to be repeatedly accessed. To maximize efficiency in handling dentries, Linux uses a dentry cache, which consists of two kinds of data structures:
- A set of dentry objects in the in-use, unused, or negative state.
- A hash table to derive the dentry object associated with a given filename and a given directory quickly. As usual, if the required object is not included in the dentry cache, the search function returns a null value.
The dentry cache also acts as a controller for an inode cache . The inodes in kernel memory that are associated with unused dentries are not discarded, because the dentry cache is still using them. Thus, the inode objects are kept in RAM and can be quickly referenced by means of the corresponding dentries.
Files Associated with a Process
Each process has its own current working directory and its own root directory. These are only two examples of data that must be maintained by the kernel to represent the interactions between a process and a filesystem. A whole data structure of type fs_struct is used for that purpose, and each process descriptor has an fs field that points to the process fs_struct structure.
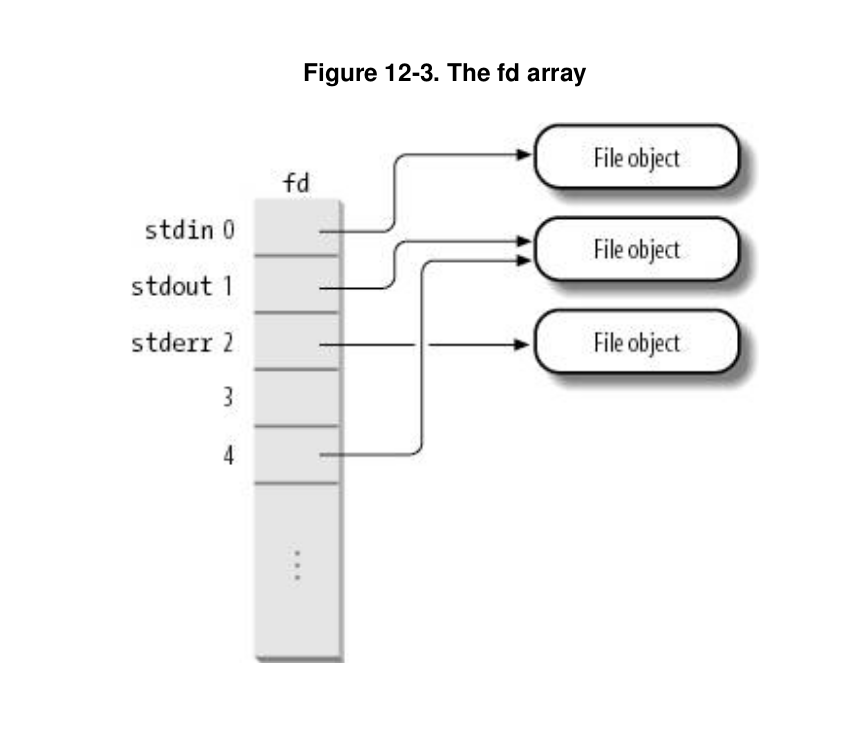
The fd field of process descriptor points to an array of pointers to file objects. The size of the array is stored in the max_fds field. Usually, fd points to the fd_array field of the files_struct structure, which includes 32 file object pointers. If the process opens more than 32 files, the kernel allocates a new, larger array of file pointers and stores its address in the fd fields; it also updates the max_fds field.
For every file with an entry in the fd array, the array index is the file descriptor. Usually, the first element (index 0) of the array is associated with the standard input of the process, the second with the standard output, and the third with the standard error (see Figure 12-3). Unix processes use the file descriptor as the main file identifier. Notice that, thanks to the dup( ) , dup2( ) , and fcntl( ) system calls, two file descriptors may refer to the same opened file that is, two elements of the array could point to the same file object. Users see this all the time when they use shell constructs such as 2>&1 to redirect the standard error to the standard output.
Filesystem Handling
Like every traditional Unix system, Linux makes use of a system’s root filesystem: it is the filesystem that is directly mounted by the kernel during the booting phase and that holds the system initialization scripts and the most essential system programs.
Other filesystems can be mounted either by the initialization scripts or directly by the users on directories of already mounted filesystems. Being a tree of directories, every filesystem has its own root directory. The directory on which a filesystem is mounted is called the mount point. A mounted filesystem is a child of the mounted filesystem to which the mount point directory belongs. For instance, the /proc virtual filesystem is a child of the system’s root filesystem (and the system’s root filesystem is the parent of /proc). The root directory of a mounted filesystem hides the content of the mount point directory of the parent filesystem, as well as the whole subtree of the parent filesystem below the mount point. The root directory of a filesystem can be different from the root directory of a process.