- Concurrency
- daemon thread
- C++ Managing threads
- C++ Sharing data between threads
- Synchronizing concurrent operations
- C++ memory models relationships
- C++ Designing lock-based concurrent data structure
- C++ Designing lock-free concurrent data structure
- C++ Difference between mutex and atomic
- C++ atomic compare_exchange_weak and compare_exchange_strong
This note is used to record the content that I read from the book C++ Concurrency IN ACTION.
Concurrency
In computer system, the cpu use the task switching to switch the tasks to achieve the concurrency.
In order to do the interleaving, the system has to perform a context switch every time it changes from one task to another, and this takes time. In order to perform a context switch, the OS has to save the CPU state and instruction pointer for the currently running task, work out which task to switch to, and reload the CPU state for the task being switched to. The CPU will then potentially have to load the memory for the instructions and data for the new task into cache, which can prevent the CPU from executing any instructions, causing further delay.
daemon thread
Detached threads are often called daemon threads after the UNIX concept of a daemon process that runs in the background without any explicit user interface.
Just like the join() of the std::thread object, you can only call the detach() method for an std::thread object for once. And you can only call the detach() function when the joinable() of the std::thread object return true.
C++ Managing threads
In c++, the class thread require the function object as the input parameter. So it is elegant and convenient to use the lambda function as the argument to pass the thread.
Passing arguments to a thread
Note that the arguments of the function passed to the thread is the internal copy inside the thread of the arguments of the caller. The following code as the instance:
void update_data_for_widget(widget_id w,widget_data& data);
void oops_again(widget_id w)
{
widget_data data;
std::thread t(update_data_for_widget,w,data);
display_status();
t.join();
process_widget_data(data);
}
Though the second argument of update_data_for_widget is a reference data type, thread constructor will not pass the reference of data in oops_again. There will be a copy of data and update_data_for_widget in the thread t will get the reference of the copy. If you really want to pass the coressponding reference of the variable in the caller function, you can use the std::ref() just like the following code.
std::thread t(update_data_for_widget,w,std::ref(data));
As the thread will copy any arguments passed by the function by default, if we pass the unique_str we must use the std::move() to change the ownership of the unique_ptr. We should take care with these situations that the resource is unique.
void process_big_object(std::unique_ptr<big_object>);
std::unique_ptr<big_object> p(new big_object);
p->prepare_data(42);
std::thread t(process_big_object,std::move(p));
If you want to pass a class member function to the thread, you can write the following code.
class X
{
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work,&my_x);
The first argument of thread() is the address of the class member function and the second argument is the address of the instance address. Then you can pass the third argument of thread() as the fist argument of the member function you pass to the thread().
Transfer Ownership of a thread
Note that the thread can only associated with only one std::thread object. It is not copyable but movable. So if you want to change the associated std::thread, you need to use the std::move() to change the ownership as the following code shows.
void some_function();
void some_other_function();
std::thread t1(some_function);
std::thread t2=std::move(t1);
t1=std::thread(some_other_function);
std::thread t3;
t3=std::move(t2);
t1=std::move(t3); //This will terminate the program
The final move t1=std::move(t3); transfers ownership of the thread running some_function back to t1 where it started. But in this case t1 already had an associated thread (which was running some_other_function ), so std::terminate() is called to terminate the program. This is done for consistency with the std::thread destructor.
Choosing the number of threads at runtime
You can use std::thread::hardware_concurrency() to get the indication of the number of threads that can truely run concurrently for a given execution of a program. On a multicore system it might be the number of CPU cores, for example. This is only a hint, and the function might return 0 if this information is not available.
Identifying threads
Thread identifiers are of type std::thread::id and can be retrieved in two ways. First, the identifier for a thread can be obtained from its associated std::thread object by calling the get_id() member function. If the std::thread object doesn’t have an associated thread of execution, the call to get_id() returns a default-constructed std::thread::id object, which indicates “not any thread.” Alternatively, the identifier for the current thread can be obtained by calling std::this_thread::get_id() , which is also defined in the
You can read the thread header file and it will show the declaration of the class id of the class thread. The class id is copyable.
join()
The act of calling join() also cleans up any storage associated with the thread, so the std::thread object is no longer associated with the now-finished thread; it isn’t associated with any thread. This means that you can call join() only once for a given thread; once you’ve called join() , the std::thread object is no longer joinable, and joinable() will return false.
detach()
If you don’t need to wait for a thread to finish, you can just detach it. This breaks the association of the thread with the std::thread object and ensures that std::terminate() won’t be called when the std::thread object is destroyed, even though the thread is still running in the background. The ownership and control of the detached thread is passed over to the c++ runtime library to ensure the resources associated with the thread are correctly reclaimed when the thread exits.
thread exception safety
Note that the destructor of std::thread will call the std::terminate if std::join or std::detach is not called by the thread object. And this will make the program abort. So take care of the exception safety of the thread to make sure that before the threads are joined or detached no exceptions are thrown. So std::packaged_task and std::future are designed for this situation. They are exception safty so that we can now just focued on the only exception safety problem that thread object itself will throw an exception when it is executing the task.
C++ Sharing data between threads
Problems of sharing data between threads
One problem is the race condition. In concurrency, a race condition is anything where the outcome depends on the relative ordering of execution of operations on two or more threads. We can use the mutex to protect the data or design the lock-free data structure.
Using mutex in C++
The point is using the same std::mutex object. You can use one std::lock_guard instance to ensure that the std::lcok instance is always locked. When the std::lock_gurad instance call its destructor, it will unlock the coressponding std::lock instance and other threads can try to lock the same std::thread instance. Just as the following code shows:
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex);
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex);
return std::find(some_list.begin(),some_list.end(),value_to_find)
!= some_list.end();
}
Don’t pass pointers and references to protected data outside the scope of the lock, whether by returning them from a function, storing them in externally visible memory, or passing them as arguments to user-supplied functions.
Avoiding deadlock
We can use the hierarchical_mutex to force the order to lock the mutex.
We can also use the std::lock() to avoid deadlock. As the following code shows:
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::lock(lhs.m,rhs.m);
std::lock_guard<std::mutex> lock_a(lhs.m,std::adopt_lock);
std::lock_guard<std::mutex> lock_b(rhs.m,std::adopt_lock);
swap(lhs.some_detail,rhs.some_detail);
}
};
At first, comparing the two objects. Then use the std::lock() to get both mutexs to avoid the deadlock. std::lock provides all-or-nothing semantics with regard to locking the supplied mutexes.
The std::adopt_lock parameter is supplied in addition to the mutex to indicate to the std::lock_guard objects that the mutexes are already locked, and they should just adopt the ownership of the existing lock on the mutex rather than attempt to lock the mutex in the constructor.
std::unique_lock and std::defer_lock
std::unique_lock is a movable scoped lock type. A unique_lock controls mutex ownership within a scope. Ownership of the mutex can be delayed until after construction and can be transferred to another unique_lock by move construction or move assignment. If a mutex lock is owned when the destructor runs ownership will be released.
Comparing std::unique_lock and std::lock_guard, we can find that both of them are use as an object to control the mutex within a scope. However, std::lock_guard can only construct to lock the mutex until the destructor is called and the mutex is unlock. We can’t do more operation with the std::lock_guard like try_lock, unlock and so on. std::unique_lock provides more flexibility for us to control the metuex object.
std::unique_lock takes more space and is a fraction slower to use than std::lock_guard. The flexibility of allowing a std::unique_lock instance not to own the mutex comes at a price: this information has to be stored, and it has to be updated.
std::call_once and std::once_flag
Suppose you have a shared resource that’s so expensive to construct that you want to do so only if it’s actually required; maybe it opens a database connection or allocates a lot of memory. Lazy initialization such as this is common in single-threaded code—each operation that requires the resource first checks to see if it has been initialized and then initializes it before use if not:
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);
}
resource_ptr->do_something();
}
// concurrency version
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex);
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);
}
lk.unlock();
resource_ptr->do_something();
}
If the shared resource itself is safe for concurrent access, the only part that needs protecting when converting this to multithreaded code is the initialization, but a naive translation such as that in the following listing can cause unnecessary serialization of threads using the resource. This is because each thread must wait on the mutex in order to check whether the resource has already been initialized.
This code is common enough, and the unnecessary serialization problematic enough, that many people have tried to come up with a better way of doing this, including the infamous Double-Checked Locking pattern: the pointer is first read without acquiring the lock 1 (in the code below), and the lock is acquired only if the pointer is NULL. The pointer is then checked again once the lock has been acquired 2 (hence the double-checked part) in case another thread has done the initialization between the first check and this thread acquiring the lock:
void undefined_behaviour_with_double_checked_locking()
{
if(!resource_ptr) // 1
{
std::lock_guard<std::mutex> lk(resource_mutex);
if(!resource_ptr) //2
{
resource_ptr.reset(new some_resource); //3
}
}
resource_ptr->do_something(); //4
}
Unfortunately, this pattern is infamous for a reason: it has the potential for nasty race conditions, because the read outside the lock 1 isn’t synchronized with the write done by another thread inside the lock 3.
The C++ Standards Committee also saw that this was an important scenario, and so the C++ Standard Library provides std::once_flag and std::call_once to handle this situation. Rather than locking a mutex and explicitly checking the pointer, every thread can just use std::call_once , safe in the knowledge that the pointer will have been initialized by some thread (in a properly synchronized fashion) by the time std::call_once returns. Use of std::call_once will typically have a lower overhead than using a mutex explicitly, especially when the initialization has already been done, so should be used in preference where it matches the required functionality. The following example shows the same operation as above, rewritten to use std::call_once. In this case, the initialization is done by calling a function, but it could just as easily have been done with an instance of a class with a function call operator. Like most of the functions in the standard library that take functions or predicates as arguments, std::call_once works with any function or callable object.
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag;
b
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag,init_resource);
resource_ptr->do_something();
}
std::call_once is only called once with the same std::once_flag varible. So in some situations we prefer the std::call_once function. They are usually used to protect shared memory during data initialzation.
Synchronizing concurrent operations
Waiting for an event or other condition
std::mutex mut;
std::queue<data_chunk> data_queue;
std::condition_variable data_cond;
void data_preparation_thread()
{
while(more_data_to_prepare())
{
data_chunk const data=prepare_data();
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
}
void data_processing_thread()
{
while(true)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(
lk,[]{return !data_queue.empty();});
data_chunk data=data_queue.front();
data_queue.pop();
lk.unlock();
process(data);
if(is_last_chunk(data))
break;
}
}
The implementation of wait() then checks the condition (by calling the supplied lambda function) and returns if it’s satisfied (the lambda function returned true ). If the condition isn’t satisfied (the lambda function returned false ), wait() unlocks the mutex and puts the thread in a blocked or waiting state. When the condition variable is notified by a call to notify_one() from the data-preparation thread, the thread wakes from its slumber (unblocks it), reacquires the lock on the mutex, and checks the condition again, returning from wait() with the mutex still locked if the condition has been satisfied. If the condition hasn’t been satisfied, the thread unlocks the mutex and resumes waiting. This is why you need the std::unique_lock rather than the std::lock_guard —the waiting thread must unlock the mutex while it’s waiting and lock it again afterward, and std::lock_guard doesn’t provide that flexibility. If the mutex remained locked while the thread was sleeping, the data-preparation thread wouldn’t be able to lock the mutex to add an item to the queue, and the waiting thread would never be able to see its condition satisfied.
Waiting for one-off events with future
The std:future
Although futures are used to communicate between threads, the future objects themselves don’t provide synchronized accesses. If multiple threads need to access a single future object, they must protect access via a mutex or other synchronization mechanism.
If you access a single std::future object from multiple threads without additional synchronization, you have a data race and undefined behavior. This is by design: std::future models unique ownership of the asynchronous result, and the one-shot nature of get() makes such concurrent access pointless anyway—only one thread can retrieve the value, because after the first call to get() there’s no value left to retrieve.
We can use the std::future to get the return value of an asynchronous task. std::async works like the std::thread. Just as the following code shows.
#include <future>
#include <iostream>
int find_the_answer_to_ltuae();
void do_other_stuff();
int main()
{
std::future<int> the_answer=std::async(find_the_answer_to_ltuae);
do_other_stuff();
std::cout<<"The answer is "<<the_answer.get()<<std::endl;
}
In most cases this is what you want, but you can specify which to use with an additional parameter to std::async before the function to call. This parameter is of the type std::launch , and can either be std::launch::deferred to indicate that the function call is to be deferred until either wait() or get() is called on the future, std::launch::async to indicate that the function must be run on its own thread, or std::launch::deferred | std::launch::async to indicate that the implementation may choose. This last option is the default. If the function call is deferred, it may never actually run.
auto f6=std::async(std::launch::async,Y(),1.2);//Run in new thread
auto f7=std::async(std::launch::deferred,baz,std::ref(x));//Run in wait() or get()
auto f8=std::async(std::launch::deferred | std::launch::async,baz,std::ref(x));
auto f9=std::async(baz,std::ref(x)); // f8 and f9 are implementation chooses
f7.wait();
std::promise()
C++ memory models relationships
There are two memory models relationships, happens-before and synchronizes-with.
The synchronizes-with relationship is something that you can get only between operations on atomic types. For synchronizes-with, the basic idea is this: a suitably tagged atomic write operation W on a variable x synchronizes-with a suitably tagged atomic read operation on x that reads the value stored by either that write ( W ), or a subsequent atomic write operation on x by the same thread that performed the initial write W , or a sequence of atomic read-modify-write operations on x (such as fetch_add() or compare_exchange_weak() ) by any thread, where the value read by the first thread in the sequence is the value written by W.
For happens-before, it is easier. If in a single thread then if one operation (A) occurs in a statement prior to another (B) in the source code, then A happens-before B. If the operations occur in the same statement, in general there’s no happens-before relationship between them, because they’re unordered.
If in multithreads, if operation A on one thread inter-thread happens-before operation B on another thread, then A happens-before B. Inter-thread happens-before is relatively simple and relies on the synchronizes-with relationship: if operation A in one thread synchronizes-with operation B in another thread, then A inter-thread happens-before B. It’s also a transitive relation: if A inter-thread happens-before B and B inter-thread happens-before C, then A inter-thread happens-before C.
C++ memory ordering for atomic operations
- Store operations, which can have memory_order_relaxed , memory_order_release , or memory_order_seq_cst ordering
- Load operations, which can have memory_order_relaxed , memory_order_consume , memory_order_acquire, or memory_order_seq_cst ordering
- Read-modify-write operations, which can have memory_order_relaxed , memory_order_consume , memory_order_acquire , memory_order_release , memory_order_acq_rel, or memory_order_seq_cst ordering The default ordering for all operations is memory_order_seq_cst.
There are six memory ordering options that can be applied to operations on atomic types: memory_order_relaxed , memory_order_consume , memory_order_acquire , memory_order_release , memory_order_acq_rel , and memory_order_seq_cst.
Unless you specify otherwise for a particular operation, the memory-ordering option for all operations on atomic types is memory_order_seq_cst , which is the most stringent of the available options. Although there are six ordering options, they represent three models:
- sequentially consistent ordering ( memory_order_seq_cst )
- acquire-release ordering ( memory_order_consume , memory_order_acquire , memory_order_release , and memory_order_acq_rel )
- relaxed ordering ( memory_order_relaxed ).
Additional synchronization instructions can be required for sequentially consistent ordering over acquire-release ordering or relaxed ordering and for acquire-release ordering over relaxed ordering. If these systems have many processors, these additional synchronization instructions may take a significant amount of time, thus reducing the overall performance of the system.
For memory_order_seq_cst, it requires a single total ordering over all operations tagged memory_order_seq_cst.
For memory_order_relaxed, operations on the same variable within a single thread still obey happens-before relationships. Relaxed operations on different variables can be freely reordered, even within the same thread. They don’t introduce synchronizes-with relationships.
For acquire-release ordering, atomic loads are acquire operations ( memory_order_acquire ), atomic stores are release operations ( memory_order_release ), and atomic read-modify-write operations (such as fetch_add() or exchange() ) are either acquire, release, or both ( memory_order_acq_rel ). Synchronization is pairwise, between the thread that does the release and the thread that does the acquire. A release operation synchronizes-with anacquire operation that reads the value written.
If you mix acquire-release operations with sequentially consistent operations, the sequentially consistent loads behave like loads with acquire semantics, and sequentially consistent stores behave like stores with release semantics. Sequentially consistent read-modify-write operations behave as both acquire and release operations. Relaxed operations are still relaxed but are bound by the additional synchronizes-with and consequent happens-before relationships introduced through the use of acquire-release semantics.
Memory_order_consume was part of the acquire-release ordering model, but it was conspicuously absent from the preceding description. This is because memory_order_consume is special: it’s all about data dependencies. There are two new relations that deal with data dependencies: dependency-ordered-before and carries-a-dependency-to. Just like sequenced-before, carries-a-dependency-to applies strictly within a single thread and essentially models the data dependency between operations; if the result of an operation A is used as an operand for an operation B, then A carries-a-dependency-to B. If the result of operation A is a value of a scalar type such as an int, then the relationship still applies if the result of A is stored in a variable, and that variable is then used as an operand for operation B. This operation is also transitive, so if A carries-a-dependency-to B, and B carries-a-dependency-to C, then A carries-a-dependency-to C.
On the other hand, the dependency-ordered-before relationship can apply between threads. It’s introduced by using atomic load operations tagged with memory_order_consume. This is a special case of memory_order_acquire that limits the synchronized data to direct dependencies; a store operation A tagged with memory_order_release , memory_order_acq_rel , or memory_order_seq_cst is dependency-ordered-before a load operation B tagged with memory_order_consume if the consume reads the value stored. This is as opposed to the synchronizes-with relationship you get if the load uses memory_order_acquire. If this operation B then carries-a-dependency-to some operation C, then A is also dependency-ordered-before C. One important use for this kind of memory ordering is where the atomic operation loads a pointer to some data. By using memory_order_consume on the load and memory_order_release on the prior store, you ensure that the pointed-to data is correctly synchronized, without imposing any synchronization requirements on any other nondependent data.
C++ atomic fences
The general idea with fences: if an acquire operation sees the result of a store that takes place after a release fence, the fence synchronizes-with that acquire operation; and if a load that takes place before an acquire fence sees the result of a release operation, the release operation synchronizes-with the acquire fence.
C++ Designing lock-based concurrent data structure
At the basic level, designing a data structure for concurrency means that multiple threads can access the data structure concurrently, either performing the same or distinct operations, and each thread will see a self-consistent view of the data structure. No data will be lost or corrupted, all invariants will be upheld, and there’ll be no problematic race conditions. Such a data structure is said to be thread-safe.
C++ Designing lock-free concurrent data structure
For a data structure to qualify as lock-free, more than one thread must be able to access the data structure concurrently. They don’t have to be able to do the same operations.
A wait-free data structure is a lock-free data structure with the additional property that every thread accessing the data structure can complete its operation within a bounded number of steps, regardless of the behavior of other threads.
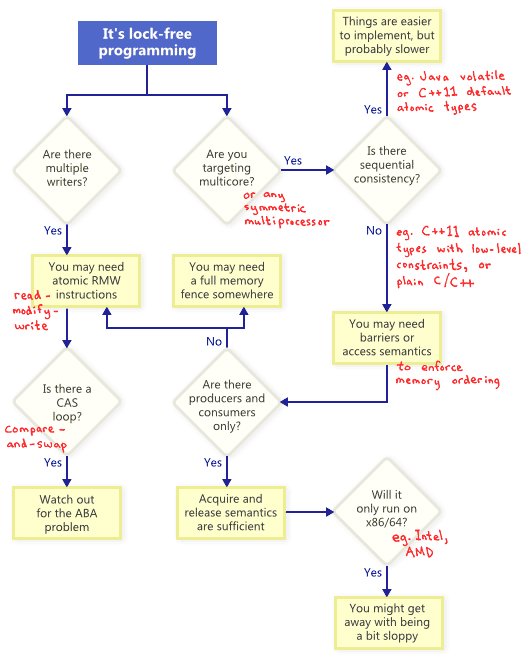
Reference about lock-free programming
C++ Difference between mutex and atomic
Although none of these examples use mutex locks directly, it’s worth bearing in mind that only std::atomic_flag is guaranteed not to use locks in the implementation. On some platforms what appears to be lock-free (atomic::is_lock_free return true) code might actually be using locks internal to the C++ Standard Library implementation. On these platforms, a simple lock-based data structure might actually be more appropriate.
For atomic operations, deadlocks are impossible with lock-free data structures because there aren’t any locks, although there is the possibility of live locks instead. A live lock occurs when two threads each try to change the data structure, but for each thread the changes made by the other require the operation to be restarted, so both threads loop and try again.
The references is shown below:
how is std::atomic implemented
where is the lock for a std::atomic
Weak and Strong Memory Model
Reference Links
C++ atomic compare_exchange_weak and compare_exchange_strong
Both of these operations are used to update the atomic content. The difference is the weak operation is allowed to fall spuriously, which means weak operation will act as the expected value is not equal to the atomic content even they are actually equal. When a compare-and-exchange is in a loop, the weak version will yield better performance on some platforms.