- ACID Properties
- Transactions and Schedules
- Concurrent Execution of Transactions
- Lock-Based Concurrency Control
- Performance of Locking
- Transaction Support in SQL
- Transaction Characteristics in SQL
- Introduction to Crash Recovery
ACID Properties
A transaction is an execution of a user program, seen by the DBMS as a series of read and write operations.
A DBMS must ensure four important properties of transactions to maintain data in the face of concurrent access and system failures:
- Users should be able to regard the execution of each transaction as atomic: Either all actions are carried out or none are. Users should not have to worry about the effect of incomplete transactions (say, when a system crash occurs).
- Each transaction, run by itself with no concurrent execution of other transactions, must preserve the consistency of the database. The DBMS assumes that consistency holds for each transaction. Ensuring this property of a transaction is the responsibility of the user.
- Users should be able to understand a transaction without considering the effect of other concurrently executing transactions, even if the DBMS interleaves the actions of several transactions for performance reasons. This property is sometimes referred to as isolation: Transactions are isolated, or protected, from the effects of concurrently scheduling other transactions.
- Once the DBMS informs the user that a transaction has been successfully completed, its effects should persist even if the system crashes before all its changes are reflected on disk. This property is called durability.
The acronym ACID is sometimes used to refer to these four properties of transactions: atomicity, consistency, isolation and durability.
Consistency and Isolation
Users are responsible for ensuring transaction consistency. That is, the user who submits a transaction must ensure that, when run to completion by itself against a ‘consistent’ database instance, the transaction will leave the database in a ‘consistent’ state. For example, the user may (naturally) have the consistency criterion that fund transfers between bank accounts should not change the total amount of money in the accounts.
The isolation property is ensured by guaranteeing that, even though actions of several transactions might be interleaved, the net effect is identical to executing all transactions one after the other in some serial order.
Atomicity and Durability
Transactions can be incomplete for three kinds of reasons. First, a transaction can be aborted, or terminated unsuccessfully, by the DBMS because some anomaly arises during execution. If a transaction is aborted by the DBMS for Some internal reason, it is automatically restarted and executed anew. Second, the system may crash (e.g., because the power supply is interrupted) while one or more transactions are in progress. Third, a transaction may encounter an unexpected situation (for example, read an unexpected data value or be unable to access some disk) and decide to abort (i.e., terminate itself).
Of course, since users think of transactions as being atomic, a transaction that is interrupted in the middle may leave the database in an inconsistent state. Therefore, a DBMS must find a way to remove the effects of partial transactions from the database. That is, it must ensure transaction atomicity: Either all of a transaction’s actions are carried out or none are. A DBMS ensures transaction atomicity by undoing the actions of incomplete transactions. This means that users can ignore incomplete transactions in thinking about how the database is modified by transactions over time. To be able to do this, the DBMS maintains a record, called the log of all writes to the database. The log is also used to ensure durability: If the system crashes before the changes made by a completed transaction are written to disk, the log is used to remember and restore these changes when the system restarts.
Transactions and Schedules
A transaction is seen by the DBMS as a series, or list, of actions. The actions that can be executed by a transaction include reads and writes of database objects. To keep our notation simple, we assume that an object O is always read into a program variable that is also named O. We can therefore denote the action of a transaction T reading an object O as $R_T(O)$; similarly, we can denote writing as $W_T(O)$. When the transaction T is clear from the context, we omit the subscript. In addition to reading and writing, each transaction must specify as its final action either commit (i.e., complete successfully) or abort (i.e., terminate and undo all the actions carried out thus far). AbortT denotes the action of T aborting, and CommitT denotes T committing.
We make two important assumptions:
- Transactions interact with each other only via database read and write operations; for example, they are not allowed to exchange messages.
- A database is a file collection of independent objects. When objects are added to or deleted from a database or there are relationships between database objects that we want to exploit for performance, some additional issues arise.
A schedule is a list of actions (reading, writing, aborting, or committing) from a set of transactions, and the order in which two actions of a transaction T appear in a schedule must be the same as the order in which they appear in T. Intuitively, a schedule represents an actual or potential execution sequence. For example, the schedule in Figure 16.1 shows an execution order for actions of two transactions T1 and T2. We move forward in time as we go down from one row to the next. We emphasize that a schedule describes the actions of transactions as seen by the DBMS. In addition to these actions, a transaction may carry out other actions, such as reading or writing from operating system files, evaluating arithmetic expressions, and so on; however, we assume that these actions do not affect other transactions; that is, the effect of a transaction on another transaction can be understood solely in terms of the common database objects that they read and write.
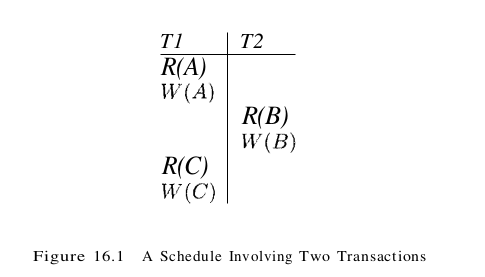
A schedule that contains either an abort or a commit for each transaction whose actions are listed in it is called a complete schedule. A complete schedule must contain all the actions of every transaction that appears in it. If the actions of different transactions are not interleaved-that is, transactions are executed from start to finish, one by one – we call the schedule a serial schedule.
Concurrent Execution of Transactions
A serializable schedule over a set S of committed transactions is a schedule whose effect on any consistent database instance is guaranteed to be identical to that of some complete serial schedule over S. That is, the database instance that results from executing the given schedule is identical to the database instance that results from executing the transactions in some serial order.
As an example, the schedule shown in Figure 16.2 is serializable. Even though the actions of T1 and T2 are interleaved, the result of this schedule is equivalent to running T1 (in its entirety) and then running T2. Intuitively, T1 ‘s read and write of B is not influenced by T2’s actions on A, and the net effect is the same if these actions are ‘swapped’ to obtain the serial schedule T1, T2.

Anomalies Due to Interleaved Execution
The first source of anomalies is that a transaction T2 could read a database object A that has been modified by another transaction T1, which has not yet committed. Such a read is called a dirty read.
The second way in which anomalous behavior could result is that a transaction T2 could change the value of an object A that has been read by transaction T1, while T1 is still in progress. If T1 tries to read the value of A again, it will get a different result, even though it has not modified A in the meantime. This situation could not arise in a serial execution of two transactions; it is called an unrepeatable read.
The third source of anomalous behavior is that a transaction T2 could overwrite the value of an object A, which has already been modified by a transaction T1, while T1 is still in progress. Even if T2 does not read the value of A written by T1. The problem is that we have a lost update.
Schedules Involving Aborted Transactions
We now extend our definition of serializability to include aborted transactions. Intuitively, all actions of aborted transactions are to be undone, and we can therefore imagine that they were never carried out to begin with. Using this intuition, we extend the definition of a serializable schedule as follows: A serializable schedule over a set S of transactions is a schedule whose effect on any consistent database instance is guaranteed to be identical to that of some complete serial schedule over the set of committed transactions in S.
This definition of serializability relies on the actions of aborted transactions being undone completely, which may be impossible in some situations. For example, suppose that (1) an account transfer program T1 deducts $100 from account A, then (2) an interest deposit program T2 reads the current values of accounts A and B and adds 6% interest to each, then commits, and then (3) T1 is aborted. The corresponding schedule is shown in Figure 16.5.

Now, T2 has read a value for A that should never have been there. (Recall that aborted transactions effects are not supposed to be visible to other transactions.) If T2 had not yet committed, we could deal with the situation by cascading the abort of TI and also aborting T2; this process recursively aborts any transaction that read data written by T2, and so on. But T2 has already committed, and so we cannot undo its actions. We say that such a schedule is unrecoverable. In a recoverable schedule, transactions commit only after (and if) all transactions whose changes they read commit. If transactions read only the changes of committed transactions, not only is the schedule recoverable, but also aborting a transaction can be accomplished without cascading the abort to other transactions. Such a schedule is said to avoid cascading aborts.
Lock-Based Concurrency Control
A DBMS must be able to ensure that only serializable, recoverable schedules are allowed and that no actions of committed transactions are lost while undoing aborted transactions. A DBMS typically uses a locking protocol to achieve this.
Strict Two-Phase Locking (Strict 2PL)
The most widely used locking protocol, called Strict Two-Phase Locking, or Strict 2PL, has two rules.
- If a transaction T wants to read (respectively, modify) an object, it first requests a shared (respectively, exclusive) lock on the object.
- All locks held by a transaction are released when the transaction is completed.
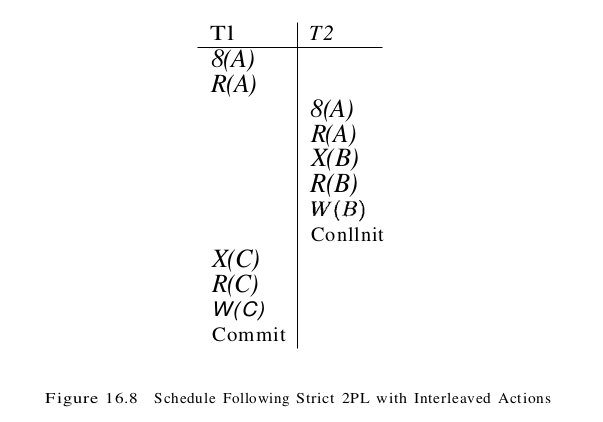
We denote the action of a transaction T requesting a shared (respectively, exclusive) lock on object O as ST(0) (respectively, XT(O)) and omit the subscript denoting the transaction when it is clear from the context. In general, however, the actions of different transactions could be interleaved. As an example, consider the interleaving of two transactions shown in Figure 16.8, which is permitted by the Strict 2PL protocol.
Performance of Locking
Throughput can be increased in three ways (other than buying a faster system):
- By locking the smallest sized objects possible (reducing the likelihood that two transactions need the same lock).
- By reducing the time that transaction hold locks (so that other transactions are blocked for a shorter time).
- By reducing hot spots. A hot spot is a database object that is frequently accessed and modified, and causes a lot of blocking delays. Hot spots can significantly affect performance.
The granularity of locking is largely determined by the database system’s implementation of locking, and application programmers and the DBA have little control over it.
Transaction Support in SQL
Creating and Terminating Transactions
A transaction is automatically started when a user executes a statement that accesses either the database or the catalogs, such as a SELECT query, an UPDATE command, or a CREATE TABLE statement. Once a transaction is started, other statements can be executed as part of this transaction until the transaction is terminated by either a COMMIT command or a ROLLBACK (the SQL keyword for abort) command.
In SQL:1999, two new features are provided to support applications that involve long-running transactions, or that must run several transactions one after the other. To understand these extensions, recall that all the actions of a given transaction are executed in order, regardless of how the actions of different transactions are interleaved. We can think of each transaction as a sequence of steps. The first feature, called a savepoint, allows us to identify a point in a transaction and selectively roll back operations carried out after this point. This is especially useful if the transaction carries out what-if kinds of operations, and wishes to undo or keep the changes based on the results. This can be accomplished by defining savepoints. If we define three savepoints A, B, and C in that order, and then rollback to A, all operations since A are undone, including the creation of savepoints B and C. Indeed, the savepoint A is itself undone when we roll back to it, and we must re-establish it (through another savepoint command) if we wish to be able to roll back to it again.
From a locking standpoint, locks obtained after savepoint A can be released when we roll back to A. It is instructive to compare the use of savepoints with the alternative of executing a series of transactions (i.e., treat all operations in between two consecutive savepoints as a new transaction).
The savepoint mechanism offers two advantages. First, we can roll back over several savepoints. In the alternative approach, we can roll back only the most recent transaction, which is equivalent to rolling back to the most recent savepoint, Second, the overhead of initiating several transactions is avoided. Even with the use of savepoints, certain applications might require us to run several transactions one after the other. To minimize the overhead in such situations, SQL:1999 introduces another feature, called chained transactions, We can commit or roll back a transaction and immediately initiate another transaction, This is done by using the optional keywords AND CHAIN in the COMMIT and ROLLBACK statements.
What Should We Lock
An important question to consider in the context of SQL is what the DBMS should treat as an object when setting locks for a given SQL statement (that is part of a transaction). Consider the following query:
SELECT S.rating, MIN (S.age)
FROM Sailors S
WHERE S.rating = 8
Suppose that this query runs as part of transaction T1 and an SQL statement that modifies the age of a given sailor, say Joe, with rating = 8 runs as part of transaction T2. What ‘objects’ should the DBMS lock when executing these transactions? Intuitively, we must detect a conflict between these transactions. The DBMS could set a shared lock on the entire Sailors table for T1 and set an exclusive lock on Sailors for T2, which would ensure that the two transactions are executed in a serializable manner. However, this approach yields low concurrency, and we can do better by locking smaller objects, reflecting what each transaction actually accesses. Thus, the DBMS could set a shared lock on every row with rating=8 for transaction T1 and set an exclusive lock on just the row for the modified tuple for transaction T2. Now, other read-only transactions that do not involve rating=8 rows can proceed without waiting for T1 or T2.
As this example illustrates, the DBMS can lock objects at different granularities: we can lock entire tables or set row-level locks. The latter approach is taken in current systems because it offers much better performance. In practice, while row-level locking is generally better, the choice of locking granularity is complicated. For example, a transaction that examines several rows and modifies those that satisfy some condition might be best served by setting shared locks on the entire table and setting exclusive locks on those rows it wants to modify.
A second point to note is that SQL statements conceptually access a collection of rows described by a selection predicate. In the preceding example, transaction T1 accesses all rows with rating=8. We suggested that this could be dealt with by setting shared locks on all rows in Sailors that had rating = 8. Unfortunately, this is a little too simplistic. To see why, consider an SQL statement that inserts a new sailor with mting=8 and runs as transaction T3. (Observe that this example violates our assumption of a fixed number of objects in the database, but we must obviously deal with such situations in practice.)
Suppose that the DBMS sets shared locks on every existing Sailors row with rating = 8 for T1. This does not prevent transaction T3 from creating a brand new row with mting = 8 and setting an exclusive lock on this row. If this new row has a smaller age value than existing rows, T1 returns an answer that depends on when it executed relative to T2. However, our locking scheme imposes no relative order on these two transactions. This phenomenon is called the phantom problem: A transaction retrieves a collection of objects (in SQL terms, a collection of tuples) twice and sees different results, even though it does not modify any of these tuples itself. To prevent phantoms, the DBMS must conceptually lock all possible rows with rating=8 on behalf of T1. One way to do this is to lock the entire table, at the cost of low concurrency. It is possible to take advantage of indexes to do better, but in general preventing phantoms can have a significant impact on concurrency. It may well be that the application invoking T1 can accept the potential inaccuracy due to phantoms. If so, the approach of setting shared locks on existing tuples for T1 is adequate, and offers better performance. SQL allows a programmer to make this choice – and other similar choices – explicitly, as we see next.
Transaction Characteristics in SQL
In order to give programmers control over the locking overhead incurred by their transactions, SQL allows them to specify three characteristics of a transaction: access mode, diagnostics size, and isolation level. The diagnostics size determines the number of error conditions that can be recorded; we will not discuss this feature further. If the access mode is READ ONLY, the transaction is not allowed to modify the database. Thus, INSERT, DELETE, UPDATE, and CREATE commands cannot be executed. If we have to execute one of these commands, the access mode should be set to READ WRITE. For transactions with READ ONLY access mode. only shared locks need to be obtained, thereby increasing concurrency. The isolation level controls the extent to which a given transaction is exposed to the actions of other transactions executing concurrently. By choosing one of four possible isolation level settings, a user can obtain greater concurrency at the cost of increasing the transaction’s exposure to other transactions’ uncommitted changes. Isolation level choices are READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE.
The highest degree of isolation from the effects of other transactions is achieved by setting the isolation level for a transaction T to SERIALIZABLE. This isolation level ensures that T reads only the changes made by committed transactions, that no value read or written by T is changed by any other transaction until T is complete, and that if T reads a set of values based on some search condition, this set is not changed by other transactions until T is complete (i.e., T avoids the phantom phenomenon). In terms of a lock-based implementation, a SERIALIZABLE transaction obtains locks before reading or writing objects, including locks on sets of objects that it requires to be unchanged and holds them until the end, according to Strict 2PL.
REPEATABLE READ ensures that T reads only the changes made by committed transactions and no value read or written by T is changed by any other transaction until T is complete. However, T could experience the phantom phenomenon; for example, while T examines all Sailors records with rating = 1, another transaction might add a new such Sailors record, which is missed by T. A REPEATABLE READ transaction sets the same locks as a SERIALIZABLE transaction, except that it does not do index locking; that is, it locks only individual objects, not sets of objects.
READ COMMITTED ensures that T reads only the changes made by committed transactions, and that no value written by T is changed by any other transaction until T is complete. However, a value read by T may well be modified by another transaction while T is still in progress, and T is exposed to the phantom problem. A READ COMMITTED transaction obtains exclusive locks before writing objects and holds these locks until the end. It also obtains shared locks before reading objects, but these locks are released immediately; their only effect is to guarantee that the transaction that last modified the object is complete. (This guarantee relies on the fact that every SQL transaction obtains exclusive locks before writing objects and holds exclusive locks until the end.)
A READ UNCOMMITTED transaction T can read changes made to an object by an ongoing transaction; obviously, the object can be changed further while T is in progress, and T is also vulnerable to the phantom problem. A READ UNCOMMITTED transaction does not obtain shared locks before reading objects. This mode represents the greatest exposure to uncommitted changes of other transactions so much so that SQL prohibits such a transaction from making any changes itself – a READ UNCOMMITTED transaction is required to have an access mode of READ ONLY. Since such a transaction obtains no locks for reading objects and it is not allowed to write objects (and therefore never requests exclusive locks), it never makes any lock requests.
The SERIALIZABLE isolation level is generally the safest and is recommended for most transactions. Some transactions, however, can run with a lower isolation level, and the smaller number of locks requested can contribute to improved system performance. For example, a statistical query that finds the average sailor age can be run at the READ COMMITTED level or even the READ UNCOMMITTED level, because a few incorrect or missing values do not significantly affect the result if the number of sailors is large.
Introduction to Crash Recovery
The recovery manager of a DBMS is responsible for ensuring transaction atomicity and durability. It ensures atomicity by undoing the actions of transactions that do not commit, and durability by making sure that all actions of committed transactions survive system crashes, (e.g., a core dump caused by a bus error) and media failures (e.g., a disk is corrupted). When a DBMS is restarted after crashes, the recovery manager is given control and must bring the database to a consistent state. The recovery manager is also responsible for undoing the actions of an aborted transaction. To see what it takes to implement a recovery manager, it is necessary to understand what happens during normal execution. The transaction manager of a DBMS controls the execution of transactions. Before reading and writing objects during normal execution, locks must be acquired (and released at some later time) according to a chosen locking protocol.
Stealing Frames and Forcing Pages
With respect to writing objects, two additional questions arise:
- Can the changes made to an object O in the buffer pool by a transaction T be written to disk before T commits? Such writes are executed when another transaction wants to bring in a page and the buffer manager chooses to replace the frame containing O; of course, this page must have been unpinned by T. If such writes are allowed, we say that a steal approach is used. (Informally, the second transaction ‘steals’ a frame from T.)
- When a transaction commits, must we ensure that all the changes it has made to objects in the buffer pool are immediately forced to disk? If so. we say that a force approach is used.
From the standpoint of implementing a recovery manager, it is simplest to use a buffer manager with a no-steal, force approach. If a no-steal approach is used, we do not have to undo the changes of an aborted transaction (because these changes have not been written to disk) and if a force approach is used, we do not have to redo the changes of a committed transaction if there is a subsequent crash (because all these changes are guaranteed to have been written to disk at commit time). However, these policies have important drawbacks. The no-steal approach assumes that all pages modified by ongoing transactions can be accommodated in the buffer pool, and in the presence of large transactions (typically run in batch mode, e.g., payroll processing), this assumption is unrealistic. The force approach results in excessive page I/O costs. If a highly used page is updated in succession by 20 transactions, it would be written to disk 20 times. With a no-force approach, on the other hand, the in-memory copy of the page would be successively modified and written to disk just once, reflecting the effects of all 20 updates, when the page is eventually replaced in the buffer pool (in accordance with the buffer manager’s page replacement policy). For these reasons, most systems use a steal, no-force approach. Thus, if a frame is dirty and chosen for replacement, the page it contains is written to disk even if the modifying transaction is still active (steal); in addition, pages in the buffer pool that are modified by a transaction are not forced to disk when the transaction commits (no-force).