- socket Function
- connect Function
- bind function
- listen Function
- accept Function
- fork and exec Function
- close Function
- shutdown Function
- getsockname and getpeername Functions
- TCP Client/Server Example
- POSIX Signal Handling
- Handling SIGCHLD Signals
- wait and waitpid Functions
Figure 4.1 shows a timeline of the typical scenario that takes place between a TCP client and server. First, the server is started, then sometime later, a client is started that connects to the server. We assume that the client sends a request to the server, the server processes the request, and the server sends a reply back to the client. This continues until the client closes its end of the connection, which sends an end-of-file notification to the server. The server then closes its end of the connection and either terminates or waits for a new client connection.

socket Function
To perform network I/O, the first thing a process must do is call the socket function, specifying the type of communication protocol desired (TCP using IPv4, UDP using IPv6, Unix domain stream protocol, etc.).
#include <sys/socket.h>
int socket (int family, int type, int protocol );
//Returns: non-negative descriptor if OK, -1 on error
family specifies the protocol family and is one of the constants shown in Figure 4.2. This argument is often referred to as domain instead of family. The socket type is one of the constants shown in Figure 4.3. The protocol argument to the socket function should be set to the specific protocol type found in Figure 4.4, or 0 to select the system’s default for the given combination of family and type. Not all combinations of socket family and type are valid. Figure 4.5 shows the valid combinations, along with the actual protocols that are valid for each pair. The boxes marked “Yes” are valid but do not have handy acronyms. The blank boxes are not supported.


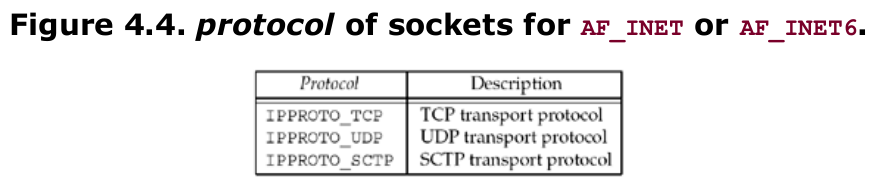

On success, the socket function returns a small non-negative integer value, similar to a file descriptor. We call this a socket descriptor, or a sockfd. To obtain this socket descriptor, all we have specified is a protocol family (IPv4, IPv6, or Unix) and the socket type (stream, datagram, or raw). We have not yet specified either the local protocol address or the foreign protocol address.
Socket Options
There are various ways to get and set the options that affect a socket:
- The getsockopt and setsockopt functions
- The fcntl function
- The ioctl function
getsockopt and setsockopt Functions
These two functions apply only to sockets.
#include <sys/socket.h>
int getsockopt ( int sockfd, int level, int optname, void * optval, socklen_t *optlen);
int setsockopt ( int sockfd, int level, int optname, const void * optval socklen_t optlen);
//Both return: 0 if OK, 1 on error
sockfd must refer to an open socket descriptor. level specifies the code in the system that interprets the option: the general socket code or some protocol-specific code (e.g., IPv4, IPv6, TCP, or SCTP).
optval is a pointer to a variable from which the new value of the option is fetched by setsockopt , or into which the current value of the option is stored by getsockopt. The size of this variable is specified by the final argument, as a value for setsockopt and as a value-result for getsockopt.
fcntl Function
The fcntl function provides the following features related to network programming:
- Nonblocking I/O. We can set the O_NONBLOCK file status flag using the F_SETFL command to set a socket as nonblocking.
- Signal-driven I/O. We can set the O_ASYNC file status flag using the F_SETFL command, which causes the SIGIO signal to be generated when the status of a socket changes.
- The F_SETOWN command lets us set the socket owner (the process ID or process group ID) to receive the SIGIO and SIGURG signals. The former signal is generated when signal-driven I/O is enabled for a socket (Chapter 25) and the latter signal is generated when new out-of-band data arrives for a socket
connect Function
The connect function is used by a TCP client to establish a connection with a TCP server.
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr * servaddr, socklen_t addrlen );
//Returns: 0 if OK, -1 on error
sockfd is a socket descriptor returned by the socket function. The second and third arguments are a pointer to a socket address structure and its size. The socket address structure must contain the IP address and port number of the server.
The client does not have to call bind (which we will describe in the next section) before calling connect: the kernel will choose both an ephemeral port and the source IP address if necessary.
In the case of a TCP socket, the connect function initiates TCP’s three-way handshake. The function returns only when the connection is established or an error occurs. There are several different error returns possible.
In terms of the TCP state transition diagram (Figure 2.4), connect moves from the CLOSED state (the state in which a socket begins when it is created by the socket function) to the SYN_SENT state, and then, on success, to the ESTABLISHED state. If connect fails, the socket is no longer usable and must be closed. We cannot call connect again on the socket. In Figure 11.10, we will see that when we call connect in a loop, trying each IP address for a given host until one works, each time connect fails, we must close the socket descriptor and call socket again.
bind function
The bind function assigns a local protocol address to a socket. With the Internet protocols, the protocol address is the combination of either a 32-bit IPv4 address or a 128-bit IPv6 address, along with a 16-bit TCP or UDP port number.
#include <sys/socket.h>
int bind (int sockfd, const struct sockaddr * myaddr, socklen_t addrlen );
//Returns: 0 if OK,-1 on error
Historically, the man page description of bind has said “bind assigns a name to an unnamed socket.” The use of the term “name” is confusing and gives the connotation of domain names such as foo.bar.com. The bind function has nothing to do with names. bind assigns a protocol address to a socket, and what that protocol address means depends on the protocol.
The second argument is a pointer to a protocol-specific address, and the third argument is the size of this address structure. With TCP, calling bind lets us specify a port number, an IP address, both, or neither.
Servers bind their well-known port when they start. If a TCP client or server does not do this, the kernel chooses an ephemeral port for the socket when either connect or listen is called. It is normal for a TCP client to let the kernel choose an ephemeral port, unless the application requires a reserved port, but it is rare for a TCP server to let the kernel choose an ephemeral port, since servers are known by their well-known port. Exceptions to this rule are Remote Procedure Call (RPC) servers. They normally let the kernel choose an ephemeral port for their listening socket since this port is then registered with the RPC port mapper. Clients have to contact the port mapper to obtain the ephemeral port before they can connect to the server. This also applies to RPC servers using UDP.
Normally, a TCP client does not bind an IP address to its socket. The kernel chooses the source IP address when the socket is connected, based on the outgoing interface that is used, which in turn is based on the route required to reach the server. If a TCP server does not bind an IP address to its socket, the kernel uses the destination IP address of the client’s SYN as the server’s source IP address.
If we specify a port number of 0, the kernel chooses an ephemeral port when bind is called. But if we specify a wildcard IP address, the kernel does not choose the local IP address until either the socket is connected (TCP) or a datagram is sent on the socket (UDP). With IPv4, the wildcard address is specified by the constant INADDR_ANY , whose value is normally 0. This tells the kernel to choose the IP address.
If we tell the kernel to choose an ephemeral port number for our socket, notice that bind does not return the chosen value. Indeed, it cannot return this value since the second argument to bind has the const qualifier. To obtain the value of the ephemeral port assigned by the kernel, we must call getsockname to return the protocol address.
One advantage in binding a non-wildcard IP address is that the demultiplexing of a given destination IP address to a given server process is then done by the kernel.
listen Function
The listen function is called only by a TCP server and it performs two actions:
- When a socket is created by the socket function, it is assumed to be an active socket, that is, a client socket that will issue a connect. The listen function converts an unconnected socket into a passive socket, indicating that the kernel should accept incoming connection requests directed to this socket. In terms of the TCP state transition diagram, the call to listen moves the socket from the CLOSED state to the LISTEN state.
- The second argument to this function specifies the maximum number of connections the kernel should queue for this socket.
#include <sys/socket.h>
//Returns: 0 if OK, -1 on error
#int listen (int sockfd, int backlog );
This function is normally called after both the socket and bind functions and must be called before calling the accept function.
To understand the backlog argument, we must realize that for a given listening socket, the kernel maintains two queues:
- An incomplete connection queue, which contains an entry for each SYN that has arrived from a client for which the server is awaiting completion of the TCP three-way handshake. These sockets are in the SYN_RCVD state.
- A completed connection queue, which contains an entry for each client with whom the TCP three-way handshake has completed. These sockets are in the ESTABLISHED state.
Figure 4.7 depicts these two queues for a given listening socket.

When a SYN arrives from a client, TCP creates a new entry on the incomplete queue and then responds with the second segment of the three-way handshake: the server’s SYN with an ACK of the client’s SYN. This entry will remain on the incomplete queue until the third segment of the three-way handshake arrives (the client’s ACK of the server’s SYN), or until the entry times out. (Berkeley-derived implementations have a timeout of 75 seconds for these incomplete entries.) If the three-way handshake completes normally, the entry moves from the incomplete queue to the end of the completed queue. When the process calls accept, which we will describe in the next section, the first entry on the completed queue is returned to the process, or if the queue is empty, the process is put to sleep until an entry is placed onto the completed queue.
There are several points to consider regarding the handling of these two queues.
- The backlog argument to the listen function has historically specified the maximum value for the sum of both queues.
- A problem is: What value should the application specify for the backlog, since 5 is often inadequate? There is no easy answer to this. HTTP servers now specify a larger value, but if the value specified is a constant in the source code, to increase the constant requires recompiling the server. Another method is to assume some default but allow a command-line option or an environment variable to override the default. It is always acceptable to specify a value that is larger than supported by the kernel, as the kernel should silently truncate the value to the maximum value that it supports, without returning an error.
- Manuals and books have historically said that the reason for queuing a fixed number of connections is to handle the case of the server process being busy between successive calls to accept. This implies that of the two queues, the completed queue should normally have more entries than the incomplete queue. Again, busy Web servers have shown that this is false. The reason for specifying a large backlog is because the incomplete connection queue can grow as client SYNs arrive, waiting for completion of the three-way handshake.
- If the queues are full when a client SYN arrives, TCP ignores the arriving SYN; it does not send an RST. This is because the condition is considered temporary, and the client TCP will retransmit its SYN, hopefully finding room on the queue in the near future. If the server TCP immediately responded with an RST, the client’s connect would return an error, forcing the application to handle this condition instead of letting TCP’s normal retransmission take over. Also, the client could not differentiate between an RST in response to a SYN meaning “there is no server at this port” versus “there is a server at this port but its queues are full.”
As we said, historically the backlog has specified the maximum value for the sum of both queues. During 1996, a new type of attack was launched on the Internet called SYN flooding. The hacker writes a program to send SYNs at a high rate to the victim, filling the incomplete connection queue for one or more TCP ports. (We use the term hacker to mean the attacker, as described in [Cheswick, Bellovin, and Rubin 2003].) Additionally, the source IP address of each SYN is set to a random number (this is called IP spoofing) so that the server’s SYN/ACK goes nowhere. This also prevents the server from knowing the real IP address of the hacker. By filling the incomplete queue with bogus SYNs, legitimate SYNs are not queued, providing a denial of service to legitimate clients. There are two commonly used methods of handling these attacks, summarized in [Borman 1997b]. But what is most interesting in this note is revisiting what the listen backlog really means. It should specify the maximum number of completed connections for a given socket that the kernel will queue. The purpose of having a limit on these completed connections is to stop the kernel from accepting new connection requests for a given socket when the application is not accepting them (for whatever reason). If a system implements this interpretation, as does BSD/OS 3.0, then the application need not specify huge backlog values just because the server handles lots of client requests (e.g., a busy Web server) or to provide protection against SYN flooding. The kernel handles lots of incomplete connections, regardless of whether they are legitimate or from a hacker. But even with this interpretation, scenarios do occur where the traditional value of 5 is inadequate.
accept Function
accept is called by a TCP server to return the next completed connection from the front of the completed connection queue. If the completed connection queue is empty, the process is put to sleep (assuming the default of a blocking socket).
#include <sys/socket.h>
//Returns: non-negative descriptor if OK, -1 on error
int accept (int sockfd, struct sockaddr * cliaddr, socklen_t * addrlen ) ;
The cliaddr and addrlen arguments are used to return the protocol address of the connected peer process (the client). addrlen is a value-result argument: Before the call, we set the integer value referenced by *addrlen to the size of the socket address structure pointed to by cliaddr; on return, this integer value contains the actual number of bytes stored by the kernel in the socket address structure.
If accept is successful, its return value is a brand-new descriptor automatically created by the kernel. This new descriptor refers to the TCP connection with the client. When discussing accept, we call the first argument to accept the listening socket (the descriptor created by socket and then used as the first argument to both bind and listen ), and we call the return value from accept the connected socket. It is important to differentiate between these two sockets. A given server normally creates only one listening socket, which then exists for the lifetime of the server. The kernel creates one connected socket for each client connection that is accepted (i.e., for which the TCP three-way handshake completes). When the server is finished serving a given client, the connected socket is closed.
This function returns up to three values: an integer return code that is either a new socket descriptor or an error indication, the protocol address of the client process (through the cliaddr pointer), and the size of this address (through the addrlen pointer). If we are not interested in having the protocol address of the client returned, we set both cliaddr and addrlen to null pointers.
fork and exec Function
This function (including the variants of it provided by some systems) is the only way in Unix to create a new process.
#include <unistd.h>
//Returns: 0 in child, process ID of child in parent, -1 on error
pid_t fork(void);
The reason fork returns 0 in the child, instead of the parent’s process ID, is because a child has only one parent and it can always obtain the parent’s process ID by calling getppid. A parent, on the other hand, can have any number of children, and there is no way to obtain the process IDs of its children. If a parent wants to keep track of the process IDs of all its children, it must record the return values from fork.
All descriptors open in the parent before the call to fork are shared with the child after fork returns. We will see this feature used by network servers: The parent calls accept and then calls fork. The connected socket is then shared between the parent and child. Normally, the child then reads and writes the connected socket and the parent closes the connected socket.
There are two typical uses of fork:
- A process makes a copy of itself so that one copy can handle one operation while the other copy does another task. This is typical for network servers. We will see many examples of this later in the text.
- A process wants to execute another program. Since the only way to create a new process is by calling fork, the process first calls fork to make a copy of itself, and then one of the copies (typically the child process) calls exec (described next) to replace itself with the new program. This is typical for programs such as shells.
exec replaces the current process image with the new program file, and this new program normally starts at the main function. The process ID does not change. We refer to the process that calls exec as the calling process and the newly executed program as the new program.
The following code shows the outline for a typical concurrent server.
pid_t pid;
int listenfd, connfd;
listenfd = Socket( ... );
/* fill in sockaddr_in{} with server's well-known port */
Bind(listenfd, ... );
Listen(listenfd, LISTENQ);
for ( ; ; ) {
connfd = Accept (listenfd, ... );
/* probably blocks */
if( (pid = Fork()) == 0) {
Close(listenfd);
/* child closes listening socket */
doit(connfd);
/* process the request */
Close(connfd);
/* done with this client */
exit(0);
/* child terminates */
}
Close(connfd);
/* parent closes connected socket */
}
We assume that the function doit does whatever is required to service the client. When this function returns, we explicitly close the connected socket in the child. This is not required since the next statement calls exit, and part of process termination is to close all open descriptors by the kernel. Whether to include this explicit call to close or not is a matter of personal programming taste.
Recall that calling close on a TCP socket causes a FIN to be sent, followed by the normal TCP connection termination sequence. Why doesn’t the close of connfda above by the parent terminate its connection with the client? To understand what’s happening, we must understand that every file or socket has a reference count. The reference count is maintained in the file table entry. This is a count of the number of descriptors that are currently open that refer to this file or socket. In our code example above, after socket returns, the file table entry associated with listenfd has a reference count of 1. After accept returns, the file table entry associated with connfd has a reference count of 1. But, after fork returns, both descriptors are shared (i.e., duplicated) between the parent and child, so the file table entries associated with both sockets now have a reference count of 2. Therefore, when the parent closes connfd, it just decrements the reference count from 2 to 1 and that is all. The actual cleanup and de-allocation of the socket does not happen until the reference count reaches 0. This will occur at some time later when the child closes connfd.
close Function
The normal Unix close function is also used to close a socket and terminate a TCP connection.
#include <unistd.h>
//Returns: 0 if OK, -1 on error
int close (int sockfd );
The default action of close with a TCP socket is to mark the socket as closed and return to the process immediately. The socket descriptor is no longer usable by the process: It cannot be used as an argument to read or write. But, TCP will try to send any data that is already queued to be sent to the other end, and after this occurs, the normal TCP connection termination sequence takes place.
We have mentioned that when the parent process in our concurrent server closes the connected socket, this just decrements the reference count for the descriptor. Since the reference count was still greater than 0, this call to close did not initiate TCP’s four-packet connection termination sequence. This is the behavior we want with our concurrent server with the connected socket that is shared between the parent and child.
If we really want to send a FIN on a TCP connection, the shutdown function can be used instead of close.
We must also be aware of what happens in our concurrent server if the parent does not call close for each connected socket returned by accept. First, the parent will eventually run out of descriptors, as there is usually a limit to the number of descriptors that any process can have open at any time. But more importantly, none of the client connections will be terminated. When the child closes the connected socket, its reference count will go from 2 to 1 and it will remain at 1 since the parent never closes the connect ed socket. This will prevent TCP’s connection termination sequence from occurring, and the connection will remain open.
shutdown Function
The normal way to terminate a network connection is to call the close function. But, there are two limitations with close that can be avoided with shutdown:
- close decrements the descriptor’s reference count and closes the socket only if the count reaches 0. With shutdown , we can initiate TCP’s normal connection termination sequence (the four segments beginning with a FIN in Figure 2.5), regardless of the reference count.
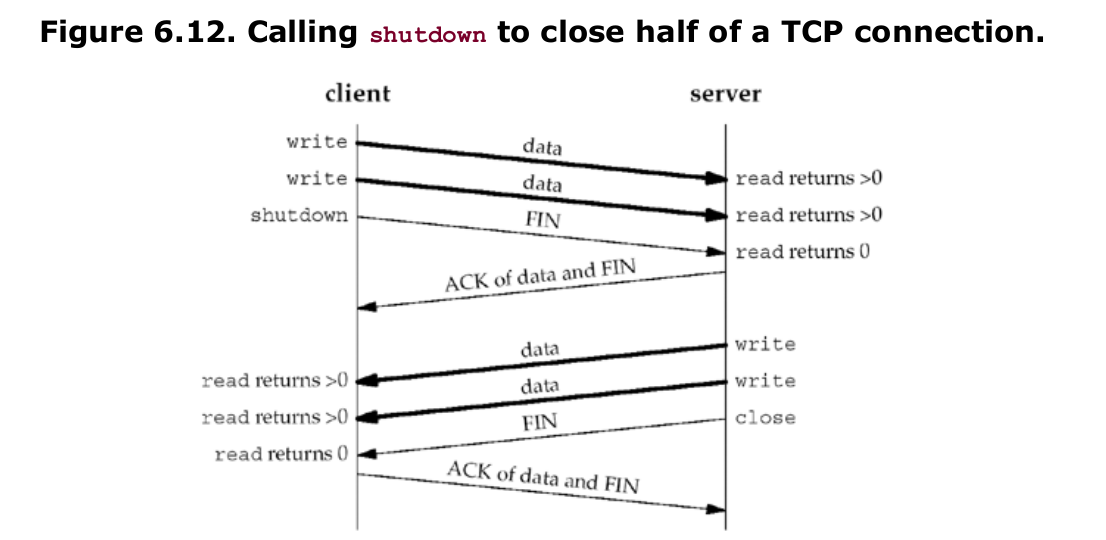
- close terminates both directions of data transfer, reading and writing. Since a TCP connection is full-duplex, there are times when we want to tell the other end that we have finished sending, even though that end might have more data to send us. This is the scenario we encountered in the previous section with batch input to our str_cli function. Figure 6.12 shows the typical function calls in this scenario.
getsockname and getpeername Functions
These two functions return either the local protocol address associated with a socket (getsockname) or the foreign protocol address associated with a socket (getpeername).
#include <sys/socket.h>
//Both return: 0 if OK, -1 on error
int getsockname(int sockfd, struct sockaddr * localaddr, socklen_t * addrlen );
int getpeername(int sockfd, struct sockaddr * peeraddr, socklen_t * addrlen );
These two functions return the protocol address associated with one of the two ends of a network connection, which for IPV4 and IPV6 is the combination of an IP address and port number. These functions have nothing to do with domain names.
These two functions are required for the following reasons:
- After connect successfully returns in a TCP client that does not call bind, getsockname returns the local IP address and local port number assigned to the connection by the kernel.
- After calling bind with a port number of 0 (telling the kernel to choose the local port number), getsockname returns the local port number that was assigned.
- getsockname can be called to obtain the address family of a socket.
- In a TCP server that binds the wildcard IP address, once a connection is established with a client (accept returns successfully), the server can call getsockname to obtain the local IP address assigned to the connection. The socket descriptor argument in this call must be that of the connected socket, and not the listening socket.
- When a server is exec ed by the process that calls accept , the only way the server can obtain the identity of the client is to call getpeername. This is what happens whenever inetd forks and execs a TCP server. Figure 4.18 shows this scenario. inetd calls accept (top left box) and two values are returned: the connected socket descriptor, connfd, is the return value of the function, and the small box we label “peer’s address” (an Internet socket address structure) contains the IP address and port number of the client. fork is called and a child of inetd is created. Since the child starts with a copy of the parent’s memory image, the socket address structure is available to the child, as is the connected socket descriptor (since the descriptors are shared between the parent and child). But when the child execs the real server (say the Telnet server that we show), the memory image of the child is replaced with the new program file for the Telnet server (i.e., the socket address structure containing the peer’s address is lost), and the connected socket descriptor remains open across the exec. One of the first function calls performed by the Telnet server is getpeername to obtain the IP address and port number of the client.

Obviously the Telnet server in this final example must know the value of connfd when it starts. There are two common ways to do this. First, the process calling exec can format the descriptor number as a character string and pass it as a command-line argument to the newly exec ed program. Alternately, a convention can be established that a certain descriptor is always set to the connected socket before calling exec. The latter is what inetd does, always setting descriptors 0, 1, and 2 to be the connected socket.
TCP Client/Server Example
The following code is a simple example for the TCP client/server model. The server will simply print out the message that it receives from the client. And the server will fork a process for each the client connection.
Here is the server code.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
void Read(int sockfd) {
char buf[1024];
int n;
while ((n = read(sockfd, buf, sizeof(buf))) > 0) {
printf("\nThe size of buffer is %d and the content of buffer is \n%s\n", n, buf);
}
}
void server0() {
struct sockaddr_in servaddr, cliaddr;
int listenfd, connfd;
pid_t childpit;
socklen_t clilen;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
if (listenfd == -1) {
perror("socket");
exit(1);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8080);
servaddr.sin_addr.s_addr = INADDR_ANY;
if (bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1) {
perror("bind");
exit(1);
}
if (listen(listenfd, 5) == -1) {
perror("listen");
exit(1);
}
for (;;) {
clilen = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr*)&cliaddr, &clilen);
if (connfd == -1) {
perror("accept");
exit(1);
}
if ((childpit = fork()) == 0) {
close(listenfd);
Read(connfd);
close(connfd);
exit(0);
}
close(connfd);
}
}
int main(int argc, char* argv[]) {
server0();
return 0;
}
Here is the client code. And you should pass the IP address to the client process. For example, run the program like ./client 127.0.0.1.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
void Write(int sockfd) {
char buf[1024];
int n;
while (fgets(buf, sizeof(buf), stdin) != NULL) {
n = write(sockfd, buf, sizeof(buf));
printf("n is %d and size of buf is %ld\n", n, strlen(buf));
}
}
void client(const char* ip) {
int sockfd;
struct sockaddr_in servaddr;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket");
exit(1);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8080);
inet_pton(AF_INET, ip, &servaddr.sin_addr);
connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr));
Write(sockfd);
close(sockfd);
}
int main(int argc, char* argv[]) {
if (argc < 2) {
printf("The IP is required\n");
exit(0);
}
client(argv[1]);
return 0;
}
POSIX Signal Handling
A signal is a notification to a process that an event has occurred. Signals are sometimes called software interrupts. Signals usually occur asynchronously. By this we mean that a process doesn’t know ahead of time exactly when a signal will occur. Signals can be sent
- By one process to another process (or to itself)
- By the kernel to a process
The SIGCHLD signal is one that is sent by the kernel whenever a process terminates, to the parent of the terminating process.
We can provide a function that is called whenever a specific signal occurs. This function is called a signal handler and this action is called catching a signal. The two signals SIGKILL and SIGSTOP cannot be caught. Our function is called with a single integer argument that is the signal number and the function returns nothing. Its function prototype is therefore
void handler (int signo);
We can ignore a signal by setting its disposition to SIG_IGN. The two signals SIGKILL and SIGSTOP cannot be ignored.
The POSIX way to establish the disposition of a signal is to call the sigaction function. This gets complicated, however, as one argument to the function is a structure that we must allocate and fill in. An easier way to set the disposition of a signal is to call the signal function. The first argument is the signal name and the second argument is either a pointer to a function or one of the constants SIG_IGN or SIG_DFL. But, signal is an historical function that predates POSIX. Different implementations provide different signal semantics when it is called, providing backward compatibility, whereas POSIX explicitly spells out the semantics when sigaction is called.
The following code shows a simple example of how to use the signal function and the sigaction function:
#include <stdio.h>
#include <signal.h>
void sigint_handler(int sig) {
printf("SIGINT is catched and its value is %d\n", sig);
//sleep(3); //to test whether the signal will be blocked
}
void testSignal() {
signal(SIGINT, sigint_handler);
printf("Press Ctrl+C will not exit\n");
while (1)
{
printf("hello world\n");
sleep(1);
}
}
void testSigaction() {
struct sigaction act, oldact;
act.sa_handler = sigint_handler;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
sigaction(SIGINT, &act, &oldact);
while (1)
{
printf("hello world\n");
sleep(1);
}
}
int main(int argc, char* argv[]) {
//testSignal();
testsigaction();
return 0;
}
This program will receive the SIGINT signal when the user presses Ctrl+C. Instead of the default behavior of exiting, the program will print out the message “SIGINT is sig” and continue to print out the message “hello world” every second. Both the testsignal and testsigaction functions work the same way.
POSIX allows us to specify a set of signals that will be blocked when our signal handler is called. Any signal that is blocked cannot be delivered to a process. We set the sa_mask member to the empty set, which means that no additional signals will be blocked while our signal handler is running. POSIX guarantees that the signal being caught is always blocked while its handler is executing. If a signal is generated one or more times while it is blocked, it is normally delivered only one time after the signal is unblocked. That is, by default, Unix signals are not queued. For example, if we call the testsigaction function with the sigint_handler sleep for 3 seconds every time it executes, the SIGINT signal will be blocked while the signal handler is running obviously. You can find even you press multiple times Crtl + C while the sigint_handler is running, only one SIGINT will be delivered to the process after the execution of sigint_handler. However, if you press Crtl + \ during the execution of the sigint_handler, the SIGQUIT signal will be delivered to the process immediately and the process will quit without blocked.
Handling SIGCHLD Signals
The purpose of the zombie state is to maintain information about the child for the parent to fetch at some later time. This information includes the process ID of the child, its termination status, and information on the resource utilization of the child (CPU time, memory, etc.). If a process terminates, and that process has children in the zombie state, the parent process ID of all the zombie children is set to 1 (the init process), which will inherit the children and clean them up (i.e., init will wait for them, which removes the zombie).
Obviously we do not want to leave zombies around. They take up space in the kernel and eventually we can run out of processes. Whenever we fork children, we must wait for them to prevent them from becoming zombies. To do this, we establish a signal handler to catch SIGCHLD, and within the handler, we call wait.
wait and waitpid Functions
#include <sys/wait.h>
pid_t wait ( int *statloc);
pid_t waitpid ( pid_t pid, int *statloc, int options);
//Both return: process ID if OK, 0 or 1 on error
wait and waitpid both return two values: the return value of the function is the process ID of the terminated child, and the termination status of the child (an integer) is returned through the statloc pointer. If there are no terminated children for the process calling wait, but the process has one or more children that are still executing, then wait blocks until the first of the existing children terminates.
waitpid gives us more control over which process to wait for and whether or not to block. First, the pid argument lets us specify the process ID that we want to wait for. A value of -1 says to wait for the first of our children to terminate. (There are other options, dealing with process group IDs, but we do not need them in this text.) The options argument lets us specify additional options. The most common option is WNOHANG. This option tells the kernel not to block if there are no terminated children.
Difference between wait and waitpid
Suppose that we run a program to build 5 client sockets and each of them connect to the server. Then the server create 5 child process to accept the connection. When the client terminates, all open descriptors are closed automatically by the kernel (we do not call close, only exit ), and all five connections are terminated at about the same time. This causes five FINs to be sent, one on each connection, which in turn causes all five server children to terminate at about the same time. This causes five SIGCHLD signals to be delivered to the parent at about the same time.
The first thing we notice is that only one printf is output, when we expect all five children to have terminated. If we execute ps, we see that the other four children still exist as zombies. Establishing a signal handler and calling wait from that handler are insufficient for preventing zombies. The problem is that all five signals are generated before the signal handler is executed, and the signal handler is executed only one time because Unix signals are normally not queued.
The correct solution is to call waitpid instead of wait. This version works because we call waitpid within a loop, fetching the status of any of our children that have terminated. We must specify the WNOHANG option: This tells waitpid not to block if there are running children that have not yet terminated. We cannot call wait in a loop, because there is no way to prevent wait from blocking if there are running children that have not yet terminated.
The purpose of this section has been to demonstrate three scenarios that we can encounter with network programming:
- We must catch the SIGCHLD signal when forking child processes.
- We must handle interrupted system calls when we catch signals.
- A SIGCHLD handler must be coded correctly using waitpid to prevent any zombies from being left around.