When a TCP client handling two inputs at the same time: standard input and a TCP socket. We encountered a problem when the client was blocked in a call to fgets (on standard input) and the server process was killed. The server TCP correctly sent a FIN to the client TCP, but since the client process was blocked reading from standard input, it never saw the EOF until it read from the socket (possibly much later). What we need is the capability to tell the kernel that we want to be notified if one or more I/O conditions are ready (i.e., input is ready to be read, or the descriptor is capable of taking more output). This capability is called I/O multiplexing and is provided by the select and poll functions.
I/O multiplexing is typically used in networking applications in the following scenarios:
- When a client is handling multiple descriptors (normally interactive input and a network socket), I/O multiplexing should be used. This is the scenario we described previously.
- It is possible, but rare, for a client to handle multiple sockets at the same time.
- If a TCP server handles both a listening socket and its connected sockets, I/O multiplexing is normally used.
- If a server handles both TCP and UDP, I/O multiplexing is normally used.
- If a server handles multiple services and perhaps multiple protocols, I/O multiplexing is normally used.
I/O Models
Before describing select and poll, we need to step back and look at the bigger picture, examining the basic differences in the five I/O models that are available to us under Unix:
- blocking I/O
- nonblocking I/O
- I/O multiplexing ( select and poll )
- signal driven I/O ( SIGIO )
- asynchronous I/O (the POSIX aio_ functions)
As we show in all the examples in this section, there are normally two distinct phases for an input operation:
- Waiting for the data to be ready
- Copying the data from the kernel to the process
For an input operation on a socket, the first step normally involves waiting for data to arrive on the network. When the packet arrives, it is copied into a buffer within the kernel. The second step is copying this data from the kernel’s buffer into our application buffer.
Blocking I/O Model
The most prevalent model for I/O is the blocking I/O model, which we have used for all our examples so far in the text. By default, all sockets are blocking. Using a datagram socket for our examples, we have the scenario shown in Figure 6.1.
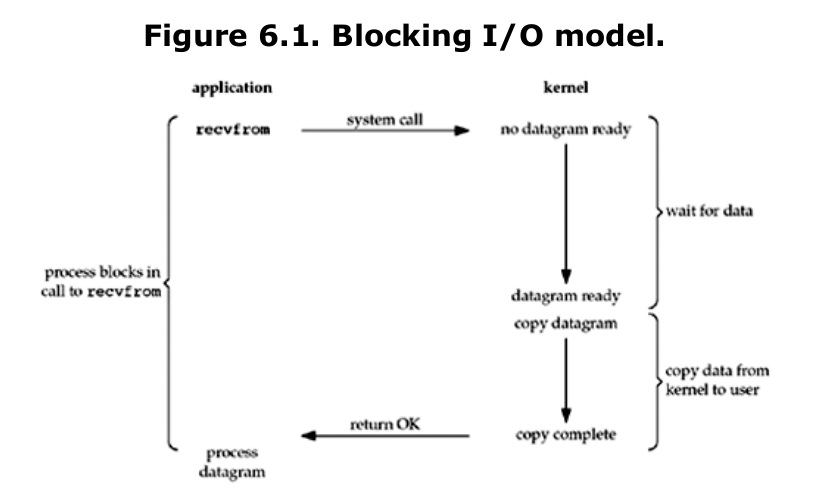
We say that our process is blocked the entire time from when it calls recvfrom until it returns. When recvfrom returns successfully, our application processes the datagram.
nonblocking I/O Model
When we set a socket to be nonblocking, we are telling the kernel “when an I/O operation that I request cannot be completed without putting the process to sleep, do not put the process to sleep, but return an error instead.” Figure 6.2 shows a summary of the example we are considering.

The first three times that we call recvfrom, there is no data to return, so the kernel immediately returns an error of EWOULDBLOCK instead. The fourth time we call recvfrom, a datagram is ready, it is copied into our application buffer, and recvfrom returns successfully. We then process the data.
When an application sits in a loop calling recvfrom on a nonblocking descriptor like this, it is called polling. The application is continually polling the kernel to see if some operation is ready. This is often a waste of CPU time, but this model is occasionally encountered, normally on systems dedicated to one function.
By default, sockets are blocking. This means that when we issue a socket call that cannot be completed immediately, our process is put to sleep, waiting for the condition to be true. We can divide the socket calls that may block into four categories:
- Input operations. These include the read, readv, recv, recvfrom, and recvmsg functions. If we call one of these input functions for a blocking TCP socket (the default), and there is no data available in the socket receive buffer, we are put to sleep until some data arrives. Since TCP is a byte stream, we will be awakened when “some” data arrives: It could be a single byte of data, or it could be a full TCP segment of data. Since UDP is a datagram protocol, if the socket receive buffer is empty for a blocking UDP socket, we are put to sleep until a UDP datagram arrives. With a nonblocking socket, if the input operation cannot be satisfied (at least one byte of data for a TCP socket or a complete datagram for a UDP socket), we see an immediate return with an error of EWOULDBLOCK.
- Output operations. These include the write, writev, send, sendto, and sendmsg functions. For a TCP socket, the kernel copies data from the application’s buffer into the socket send buffer. If there is no room in the socket send buffer for a blocking socket, the process is put to sleep until there is room. With a nonblocking TCP socket, if there is no room at all in the socket send buffer, we return immediately with an error of EWOULDBLOCK. If there is some room in the socket send buffer, the return value will be the number of bytes the kernel was able to copy into the buffer. (This is called a short count.)Note that there is no actual UDP socket send buffer. The kernel just copies the application data and moves it down the stack, prepending the UDP and IP headers. Therefore, an output operation on a blocking UDP socket (the default) will not block for the same reason as a TCP socket, but it is possible for output operations to block on some systems due to the buffering and flow control that happens within the networking code in the kernel.
- Accepting incoming connections. This is the accept function. If accept is called for a blocking socket and a new connection is not available, the process is put to sleep. If accept is called for a nonblocking socket and a new connection is not available, the error EWOULDBLOCK is returned instead.
- Initiating outgoing connections. This is the connect function for TCP. (Recall that connect can be used with UDP, but it does not cause a “real” connection to be established; it just causes the kernel to store the peer’s IP address and port number.) Recall that the establishment of a TCP connection involves a three-way handshake and the connect function does not return until the client receives the ACK of its SYN. This means that a TCP connect always blocks the calling process for at least the RTT to the server. If connect is called for a nonblocking TCP socket and the connection cannot be established immediately, the connection establishment is initiated (e.g., the first packet of TCP’s three-way handshake is sent), but the error EINPROGRESS is returned. Notice that this error differs from the error returned in the previous three
Nonblocking connect
When a TCP socket is set to nonblocking and then connect is called, connect returns immediately with an error of EINPROGRESS but the TCP three-way handshake continues. We then check for either a successful or unsuccessful completion of the connection’s establishment using select. There are three uses for a nonblocking connect:
- We can overlap other processing with the three-way handshake. A connect takes one RTT to complete and this can be anywhere from a few milliseconds on a LAN to hundreds of milliseconds or a few seconds on a WAN. There might be other processing we wish to perform during this time.
- We can establish multiple connections at the same time using this technique. This has become popular with Web browsers.
- Since we wait for the connection to be established using select, we can specify a time limit for select, allowing us to shorten the timeout for the connect. Many implementations have a timeout for connect that is between 75 seconds and several minutes. There are times when an application wants a shorter timeout, and using a nonblocking connect is one way to accomplish this.
I/O Multiplexing Model
With I/O multiplexing, we call select or poll and block in one of these two system calls, instead of blocking in the actual I/O system call. Figure 6.3 is a summary of the I/O multiplexing model.

We block in a call to select, waiting for the datagram socket to be readable. When select returns that the socket is readable, we then call recvfrom to copy the datagram into our application buffer.
Comparing Figure 6.3 to Figure 6.1, there does not appear to be any advantage, and in fact, there is a slight disadvantage because using select requires two system calls instead of one. But the advantage in using select, which we will see later in this chapter, is that we can wait for more than one descriptor to be ready.
Another closely related I/O model is to use multithreading with blocking I/O. That model very closely resembles the model described above, except that instead of using select to block on multiple file descriptors, the program uses multiple threads (one per file descriptor), and each thread is then free to call blocking system calls like recvfrom.
Signal-Driven I/O Model
We can also use signals, telling the kernel to notify us with the SIGIO signal when the descriptor is ready. We call this signal-driven I/O and show a summary of it in Figure 6.4.

We first enable the socket for signal-driven I/O and install a signal handler using the sigaction system call. The return from this system call is immediate and our process continues; it is not blocked. When the datagram is ready to be read, the SIGIO signal is generated for our process. We can either read the datagram from the signal handler by calling recvfrom and then notify the main loop that the data is ready to be processed, or we can notify the main loop and let it read the datagram.
When using signal-driven I/O, the kernel notifies us with a signal when something happens on a descriptor. Historically, this has been called asynchronous I/O, but the signal-driven I/O that we will describe is not true asynchronous I/O. The latter is normally defined as the process performing the I/O operation (say a read or write), with the kernel returning immediately after the kernel initiates the I/O operation. The process continues executing while the I/O takes place. Some form of notification is then provided to the process when the operation is complete or encounters an error.
The nonblocking I/O we described is not asynchronous I/O either. With nonblocking I/O, the kernel does not return after initiating the I/O operation; the kernel returns immediately only if the operation cannot be completed without putting the process to sleep.
Signal-driven I/O has the kernel notify us with the SIGIO signal when “something” happens on a socket.
- With a connected TCP socket, numerous conditions can cause this notification, making this feature of little use.
- With a listening TCP socket, this notification occurs when a new connection is ready to be accepted.
- With UDP, this notification means either a datagram has arrived or an asynchronous error has arrived; in both cases, we call recvfrom.
Asynchronous I/O Model
Asynchronous I/O is defined by the POSIX specification, and various differences in the real-time functions that appeared in the various standards which came together to form the current POSIX specification have been reconciled. In general, these functions work by telling the kernel to start the operation and to notify us when the entire operation (including the copy of the data from the kernel to our buffer) is complete. The main difference between this model and the signal-driven I/O model in the previous section is that with signal-driven I/O, the kernel tells us when an I/O operation can be initiated, but with asynchronous I/O, the kernel tells us when an I/O operation is complete. We show an example in Figure 6.5.

Comparision of the I/O Model
Figure 6.6 is a comparison of the five different I/O models. It shows that the main difference between the first four models is the first phase, as the second phase in the first four models is the same: the process is blocked in a call to recvfrom while the data is copied from the kernel to the caller’s buffer. Asynchronous I/O, however, handles both phases and is different from the first four.

POSIX defines these two terms as follows:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
- An asynchronous I/O operation does not cause the requesting process to be blocked.
Using these definitions, the first four I/O models blocking, nonblocking, I/O multiplexing, and signal-driven I/O are all synchronous because the actual I/O operation ( recvfrom ) blocks the process. Only the asynchronous I/O model matches the asynchronous I/O definition.
I/O Multiplexing
In this section, I will discuss the I/O multiplexing model with sepcific functions. In this section, I will create a client that send its text from the keyboard to the server and server will display the text on the screen. The client code is shown below and you should pass the IP address of the server as the first argument. For example, you can run the program as ./client 127.0.0.1.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
#include <errno.h>
void Write(int sockfd) {
char buf[1024];
int n;
while (fgets(buf, sizeof(buf), stdin) != NULL) {
n = write(sockfd, buf, strlen(buf) - 1);
printf("n is %d and size of buf is %ld\n", n, strlen(buf));
}
}
void client(const char* ip) {
int sockfd;
struct sockaddr_in servaddr;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket");
exit(1);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8080);
inet_pton(AF_INET, ip, &servaddr.sin_addr);
connect(sockfd, (struct sockaddr*)&servaddr, sizeof(servaddr));
Write(sockfd);
close(sockfd);
}
int main(int argc, char* argv[]) {
if (argc < 2) {
printf("The IP is required\n");
exit(0);
}
client(argv[1]);
return 0;
}
The code of the client is the same. However, I will create three different servers with different I/O multiplexing functions and all of them will perform the same task.
select Function
This function allows the process to instruct the kernel to wait for any one of multiple events to occur and to wake up the process only when one or more of these events occurs or when a specified amount of time has passed.
As an example, we can call select and tell the kernel to return only when:
- Any of the descriptors in the set {1, 4, 5} are ready for reading
- Any of the descriptors in the set {2, 7} are ready for writing
- Any of the descriptors in the set {1, 4} have an exception condition pending
- 10.2 seconds have elapsed
That is, we tell the kernel what descriptors we are interested in (for reading, writing, or an exception condition) and how long to wait. The descriptors in which we are interested are not restricted to sockets; any descriptor can be tested using select.
#include <sys/select.h>
#include <sys/time.h>
int select(int maxfdp1, fd_set * readset, fd_set * writeset, fd_set * exceptset, const
struct timeval * timeout ) ;
//Returns: positive count of ready descriptors, 0 on timeout, -1 on error
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
There are three possibilities:
- Wait forever. Return only when one of the specified descriptors is ready for I/O. For this, we specify the timeout argument as a null pointer.
- Wait up to a fixed amount of time. Return when one of the specified descriptors is ready for I/O, but do not wait beyond the number of seconds and microseconds specified in the timeval structure pointed to by the timeout argument.
- Do not wait at all. Return immediately after checking the descriptors. This is called polling. To specify this, the timeout argument must point to a timeval structure and the timer value (the number of seconds and microseconds specified by the structure) must be 0.
As I saw in linux with the command man select, it seems now the const qualifier of the struct timeval is removed. The date of the manual is 2019-11-19. So the value referenced by struct timeval *timeout can be updated to indicate how much the time was left.
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
A design problem is how to specify one or more descriptor values for each of these three arguments. select uses descriptor sets, typically an array of integers, with each bit in each integer corresponding to a descriptor. For example, using 32-bit integers, the first element of the array corresponds to descriptors 0 through 31, the second element of the array corresponds to descriptors 32 through 63, and so on. All the implementation details are irrelevant to the application and are hidden in the fd_set datatype and the following four macros:
/* The fd_set member is required to be an array of longs. */
typedef long int __fd_mask;
/* Some versions of <linux/posix_types.h> define this macros. */
#undef __NFDBITS
/* It's easier to assume 8-bit bytes than to get CHAR_BIT. */
#define __NFDBITS (8 * (int) sizeof (__fd_mask))
#define __FD_ELT(d) ((d) / __NFDBITS)
#define __FD_MASK(d) ((__fd_mask) (1UL << ((d) % __NFDBITS)))
/* fd_set for select and pselect. */
typedef struct
{
/* XPG4.2 requires this member name. Otherwise avoid the name
from the global namespace. */
#ifdef __USE_XOPEN
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->fds_bits)
#else
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->__fds_bits)
#endif
} fd_set;
/* Maximum number of file descriptors in `fd_set'. */
#define FD_SETSIZE __FD_SETSIZE
#ifdef __USE_MISC
/* Sometimes the fd_set member is assumed to have this type. */
typedef __fd_mask fd_mask;
/* Number of bits per word of `fd_set' (some code assumes this is 32). */
# define NFDBITS __NFDBITS
#endif
/* Access macros for `fd_set'. */
#define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp)
#define FD_CLR(fd, fdsetp) __FD_CLR (fd, fdsetp)
#define FD_ISSET(fd, fdsetp) __FD_ISSET (fd, fdsetp)
#define FD_ZERO(fdsetp) __FD_ZERO (fdsetp)
# define __FD_ZERO(fdsp) \
do { \
int __d0, __d1; \
__asm__ __volatile__ ("cld; rep; " __FD_ZERO_STOS \
: "=c" (__d0), "=D" (__d1) \
: "a" (0), "0" (sizeof (fd_set) \
/ sizeof (__fd_mask)), \
"1" (&__FDS_BITS (fdsp)[0]) \
: "memory"); \
} while (0)
#define __FD_SET(d, set) \
((void) (__FDS_BITS (set)[__FD_ELT (d)] |= __FD_MASK (d)))
#define __FD_CLR(d, set) \
((void) (__FDS_BITS (set)[__FD_ELT (d)] &= ~__FD_MASK (d)))
#define __FD_ISSET(d, set) \
((__FDS_BITS (set)[__FD_ELT (d)] & __FD_MASK (d)) != 0)
void FD_ZERO(fd_set * fdset ) ; /* clear all bits in fdset */
void FD_SET(int fd, fd_set * fdset ) ; /* turn on the bit for fd in fdset */
void FD_CLR(int fd, fd_set * fdset ) ; /* turn off the bit for fd in fdset */
void FD_ZERO(fd_set * fdset ) ; /* clear all bits in fdset */
int FD_ISSET(int fd, fd_set * fdset ) ; /* is the bit for fd on in fdset ? */
What we are describing, an array of integers using one bit per descriptor, is just one possible way to implement select. Nevertheless, it is common to refer to the individual descriptors within a descriptor set as bits, as in “turn on the bit for the listening descriptor in the read set.”
We will see later that the poll function uses a completely different representation: a variable-length array of structures with one structure per descriptor.
For example, to define a variable of type fd_set and then turn on the bits for descriptors 1, 4, and 5, we write
fd_set rset;
FD_ZERO(&rset); /*initialize the set: all bits off */
FD_SET(1, &rset); /*turn on bit for fd 1 */
FD_SET(4, &rset); /*turn on bit for fd 4 */
FD_SET(5, &rset); /*turn on bit for fd 5 */
Any of the middle three arguments to select, readset, writeset, or exceptset, can be specified as a null pointer if we are not interested in that condition. Indeed, if all three pointers are null, then we have a higher precision timer than the normal Unix sleep function (which sleeps for multiples of a second). The poll function provides similar functionality.
The maxfdp1 argument specifies the number of descriptors to be tested. Its value is the maximum descriptor to be tested plus one (hence our name of maxfdp1). The descriptors 0, 1, 2, up through and including (maxfdp1 - 1) are tested. The maxfdp1 argument forces us to calculate the largest descriptor that we are interested in and then tell the kernel this value. For example, given the previous code that turns on the indicators for descriptors 1, 4, and 5, the maxfdp1 value is 6. The reason it is 6 and not 5 is that we are specifying the number of descriptors, not the largest value, and descriptors start at 0.
select modifies the descriptor sets pointed to by the readset, writeset, and exceptset pointers. These three arguments are value-result arguments. When we call the function, we specify the values of the descriptors that we are interested in, and on return, the result indicates which descriptors are ready. So it is very important to remember that you should store the final fd_set and the current returned fd_set separately.
We use the FD_ISSET macro on return to test a specific descriptor in an fd_set structure. Any descriptor that is not ready on return will have its corresponding bit cleared in the descriptor set. To handle this, we turn on all the bits in which we are interested in all the descriptor sets each time we call select.
The two most common programming errors when using select are to forget to add one to the largest descriptor number and to forget that the descriptor sets are value-result arguments. The second error results in select being called with a bit set to 0 in the descriptor set, when we think that bit is 1.
The return value from this function indicates the total number of bits that are ready across all the descriptor sets. If the timer value expires before any of the descriptors are ready, a value of 0 is returned. A return value of -1 indicates an error (which can happen, for example, if the function is interrupted by a caught signal).
We have been talking about waiting for a descriptor to become ready for I/O (reading or writing) or to have an exception condition pending on it (out-of-band data). While readability and writability are obvious for descriptors such as regular files, we must be more specific about the conditions that cause select to return “ready” for sockets
- A socket is ready for reading if any of the following four conditions is true:
- The number of bytes of data in the socket receive buffer is greater than or equal to the current size of the low-water mark for the socket receive buffer. A read operation on the socket will not block and will return a value greater than 0 (i.e., the data that is ready to be read). We can set this low-water mark using the SO_RCVLOWAT socket option. It defaults to 1 for TCP and UDP sockets.
- The read half of the connection is closed (i.e., a TCP connection that has received a FIN). A read operation on the socket will not block and will return 0 (i.e., EOF).
- The socket is a listening socket and the number of completed connections is nonzero. An accept on the listening socket will normally not block. However there is some situation that the accept can block.
- A socket error is pending. A read operation on the socket will not block and will return an error (-1) with errno set to the specific error condition. These pending errors can also be fetched and cleared by calling getsockopt and specifying the SO_ERROR socket option.
- A socket is ready for writing if any of the following four conditions is true:
- The number of bytes of available space in the socket send buffer is greater than or equal to the current size of the low-water mark for the socket send buffer and either: (i) the socket is connected, or (ii) the socket does not require a connection (e.g., UDP). This means that if we set the socket to nonblocking, a write operation will not block and will return a positive value (e.g., the number of bytes accepted by the transport layer). We can set this low-water mark using the SO_SNDLOWAT socket option. This low-water mark normally defaults to 2048 for TCP and UDP sockets.
- The write half of the connection is closed. A write operation on the socket will generate SIGPIPE.
- A socket using a non-blocking connect has completed the connection, or the connect has failed.
- A socket error is pending. A write operation on the socket will not block and will return an error (-1) with errno set to the specific error condition. These pending errors can also be fetched and cleared by calling getsockopt with the SO_ERROR socket option.
- A socket has an exception condition pending if there is out-of-band data for the socket or the socket is still at the out-of-band mark.
The following code is a simple example of how to use select to wait for a socket to become ready for reading.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
#include <sys/select.h>
#include <poll.h>
#include <sys/epoll.h>
#include <sys/time.h>
#include <sys/types.h>
void serverSelect() {
int listenfd, connfd, nfds, res, clients[FD_SETSIZE], i, maxi = -1;
ssize_t n;
struct sockaddr_in servaddr, cliaddr;
socklen_t clilen;
fd_set rset, allset;
pid_t childpid;
char buf[1024];
//struct timeval time;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(8080);
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr));
listen(listenfd, 1024);
FD_ZERO(&allset);
FD_SET(listenfd, &allset);
nfds = listenfd + 1;
for (i = 0; i < FD_SETSIZE; i++) {
clients[i] = -1;
}
for (;;) {
rset = allset;
res = select(nfds, &rset, NULL, NULL, NULL);
if (FD_ISSET(listenfd, &rset)) {
clilen = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr*)&cliaddr, &clilen);
FD_SET(connfd, &allset);
if (connfd >= nfds) {
nfds = connfd + 1;
}
for (i = 0; i < FD_SETSIZE; i++) {
if (clients[i] == -1) {
clients[i] = connfd;
maxi = (i >= maxi)? i : maxi;
break;
}
}
if (--res <= 0) {
continue;
}
}
for (i = 0; i <= maxi; i++) {
if (clients[i] == -1) {
continue;
}
if (FD_ISSET(clients[i], &rset)) {
if ((n = read(clients[i], buf, sizeof(buf))) > 0) {
printf("\nThe client fd is %d. The size of buffer is %ld and the content of buffer is \n%s\n", clients[i], n, buf);
}
else {
close(clients[i]);
FD_CLR(clients[i], &allset);
clients[i] = -1;
}
if (--res <= 0) {
break;
}
}
}
}
}
int main(int argc, char* argv[]) {
serverSelect();
return 0;
}
poll Function
poll provides functionality that is similar to select, but poll provides additional information when dealing with STREAMS devices.
#include <poll.h>
int poll (struct pollfd * fdarray, unsigned long nfds, int timeout ) ;
//Returns: count of ready descriptors, 0 on timeout, 1 on error
struct pollfd {
int fd; /* descriptor to check */
short events; /* events of interest on fd */
short revents; /* events that occurred on fd */
};
The first argument of poll is a pointer to the first element of an array of structures. Each element of the array is a pollfd structure that specifies the conditions to be tested for a given descriptor, fd. In the structure pollfd, the field fd contains a file descriptor for an open file. If this field is negative, then the corresponding events field is ignored and the revents field returns zero. (This provides an easy way of ignoring a file descriptor for a single poll() call: simply negate the fd field. Note, however, that this technique can’t be used to ignore file descriptor 0.) The field events is an input parameter, a bit mask specifying the events the application is interested in for the file descriptor fd. This field may be specified as zero, in which case the only events that can be returned in revents are POLLHUP, POLLERR, and POLLNVAL. The field revents is an output parameter, filled by the kernel with the events that actually occurred. The bits returned in revents can include any of those specified in events, or one of the values POLLERR, POLLHUP, or POLLNVAL. (These three bits are meaningless in the events field, and will be set in the revents field whenever the corresponding condition is true.) If none of the events requested (and no error) has occurred for any of the file descriptors, then poll() blocks until one of the events occurs. The timeout argument specifies the number of milliseconds that poll() should block waiting for a file descriptor to become ready. The call will block until either:
- a file descriptor becomes ready;
- the call is interrupted by a signal handler; or
- the timeout expires.
Note that the timeout interval will be rounded up to the system clock granularity, and kernel scheduling delays mean that the blocking interval may overrun by a small amount. Specifying a negative value in timeout means an infinite timeout. Specifying a timeout of zero causes poll() to return immediately, even if no file descriptors are ready.
Figure 6.23 shows the constants used to specify the events flag and to test the revents flag against.
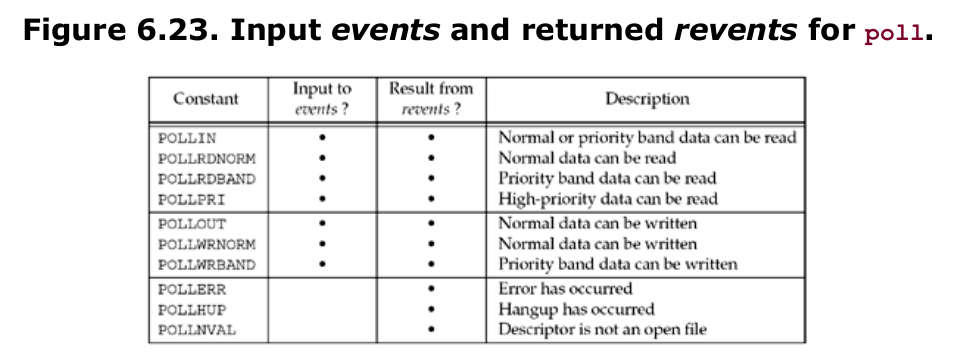
With regard to TCP and UDP sockets, the following conditions cause poll to return the specified revent. Unfortunately, POSIX leaves many holes (i.e., optional ways to return the same condition) in its definition of poll.
- All regular TCP data and all UDP data is considered normal.
- TCP’s out-of-band data is considered priority band.
- When the read half of a TCP connection is closed (e.g., a FIN is received), this is also considered normal data and a subsequent read operation will return 0.
- The presence of an error for a TCP connection can be considered either normal data or an error ( POLLERR ). In either case, a subsequent read will return 1 with errno set to the appropriate value. This handles conditions such as the receipt of an RST or a timeout.
- The availability of a new connection on a listening socket can be considered either normal data or priority data. Most implementations consider this normal data.
- The completion of a nonblocking connect is considered to make a socket writable.
The number of elements in the array of structures is specified by the nfds argument. Historically, this argument has been an unsigned long, which seems excessive. An unsigned int would be adequate. Unix 98 defines a new datatype for this argument: nfds_t.
Recall our discussion about FD_SETSIZE and the maximum number of descriptors per descriptor set versus the maximum number of descriptors per process. We do not have that problem with poll since it is the caller’s responsibility to allocate an array of pollfd structures and then tell the kernel the number of elements in the array. There is no fixed-size datatype similar to fd_set that the kernel knows about.
The following code is a simple example that server useing poll to handle multiple connections of clients.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
#include <sys/select.h>
#include <poll.h>
#include <sys/epoll.h>
#include <sys/time.h>
#include <sys/types.h>
#include <errno.h>
void serverPoll() {
int listenfd, connfd, i, maxi, nready, timeout = -1;
struct sockaddr_in servaddr, cliaddr;
socklen_t clilen;
const int MAX_LEN = 1024;
struct pollfd clients[MAX_LEN];
char buf[MAX_LEN];
ssize_t n;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_port = htons(8080);
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr));
listen(listenfd, MAX_LEN);
clients[0].fd = listenfd;
clients[0].events = POLLIN;
for (i = 1; i < MAX_LEN; i++) {
clients[i].fd = -1;
}
maxi = 0;
for (;;) {
nready = poll(clients, maxi + 1, timeout);
if (clients[0].revents & POLLIN) {
clilen = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr*)&cliaddr, &clilen);
for (i = 1; i < MAX_LEN; i++) {
if (clients[i].fd == -1) {
clients[i].fd = connfd;
clients[i].events = POLLIN;
maxi = (i > maxi) ? i : maxi;
break;
}
}
if (--nready <= 0) {
continue;
}
}
for (i = 1; i <= maxi; i++) {
if (clients[i].fd == -1) {
continue;
}
if (clients[i].revents & (POLLIN | POLLERR)) {
if ((n = read(clients[i].fd, buf, sizeof(buf))) < 0) {
if (errno == ECONNRESET) {
close(clients[i].fd);
printf("The connection %d aborted\n", clients[i].fd);
clients[i].fd = -1;
}
else {
printf("Read error and errno is %d\n", errno);
}
}
else if (n == 0) {
close(clients[i].fd);
clients[i].fd = -1;
}
else {
printf("\nThe client fd is %d. The size of buffer is %ld and the content of buffer is \n%s\n", clients[i].fd, n, buf);
}
if (--nready <= 0) {
break;
}
}
}
}
}
int main(int argc, char* argv[]) {
//server0();
//serverSelect();
serverPoll();
//serverEpoll();
return 0;
}
epoll Function
The epoll API is Linux-specific. Some other systems provide similar mechanisms, for example, FreeBSD has kqueue, and Solaris has /dev/poll. The epoll API performs a similar task to poll(2): monitoring multiple file descriptors to see if I/O is possible on any of them. The epoll API can be used either as an edge-triggered or a level-triggered interface and scales well to large numbers of watched file descriptors.
The central concept of the epoll API is the epoll instance, an in-kernel data structure which, from a user-space perspective, can be considered as a container for two lists:
- The interest list (sometimes also called the epoll set): the set of file descriptors that the process has registered an interest in monitoring.
- The ready list: the set of file descriptors that are “ready” for I/O. The ready list is a subset of (or, more precisely, a set of references to) the file descriptors in the interest list that is dynamically populated by the kernel as a result of I/O activity on those file descriptors.
The following system calls are provided to create and manage an epoll instance:
- epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends the functionality of epoll_create(2).)
- Interest in particular file descriptors is then registered via epoll_ctl(2), which adds items to the interest list of the epoll instance.
- epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available. (This system call can be thought of as fetching items from the ready list of the epoll instance.)
epoll_create(int size) creates a new epoll(7) instance. Since Linux 2.6.8, the size argument is ignored, but must be greater than zero; epoll_create() returns a file descriptor referring to the new epoll instance. This file descriptor is used for all the subsequent calls to the epoll interface. When no longer required, the file descriptor returned by epoll_create() should be closed by using close(2). When all file descriptors referring to an epoll instance have been closed, the kernel destroys the instance and releases the associated resources for reuse. On success, epoll_create() returns a nonnegative file descriptor. On error, -1 is returned, and errno is set to indicate the error.
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
The system call epoll_ctl is used to add, modify, or remove entries in the interest list of the epoll(7) instance referred to by the file descriptor epfd. It requests that the operation op be performed for the target file descriptor, fd.
Valid values for the op argument are:
- EPOLL_CTL_ADD. Add fd to the interest list and associate the settings specified in event with the internal file linked to fd.
- EPOLL_CTL_MOD. Change the settings associated with fd in the interest list to the new settings specified in event.
- EPOLL_CTL_DEL. Remove (deregister) the target file descriptor fd from the interest list. The event argument is ignored and can be NULL.
The event argument describes the object linked to the file descriptor fd. The struct epoll_event is defined as:
//epoll.h
typedef union epoll_data
{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event
{
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
} __EPOLL_PACKED;
The events member is a bit mask composed by ORing together zero or more of the following available event types:
- EPOLLIN. The associated file is available for read(2) operations.
- EPOLLOUT. The associated file is available for write(2) operations
- EPOLLET. Sets the Edge Triggered behavior for the associated file descriptor. The default behavior for epoll is Level Triggered.
There are some other event types but I don’t display here. You can get more details about them from the manual of epoll_ctl. When successful, epoll_ctl() returns zero. When an error occurs, epoll_ctl() returns -1 and errno is set appropriately.
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);
int epoll_pwait(int epfd, struct epoll_event *events,
int maxevents, int timeout,
const sigset_t *sigmask);
The epoll_wait() system call waits for events on the epoll(7) instance referred to by the file descriptor epfd. The memory area pointed to by events will contain the events that will be available for the caller. Up to maxevents are returned by epoll_wait(). The maxevents argument must be greater than zero.
When successful, epoll_wait() returns the number of file descriptors ready for the requested I/O, or zero if no file descriptor became ready during the requested timeout milliseconds. When an error occurs, epoll_wait() returns -1 and errno is set appropriately.
Level-triggered and edge-triggered
The epoll event distribution interface is able to behave both as edge-triggered (ET) and as level-triggered (LT). The difference between the two mechanisms can be described as follows. Suppose that this scenario happens:
- The file descriptor that represents the read side of a pipe (rfd) is registered on the epoll instance.
- A pipe writer writes 2 kB of data on the write side of the pipe.
- A call to epoll_wait(2) is done that will return rfd as a ready file descriptor.
- The pipe reader reads 1 kB of data from rfd.
- A call to epoll_wait(2) is done.
If the rfd file descriptor has been added to the epoll interface using the EPOLLET (edge-triggered) flag, the call to epoll_wait(2) done in step 5 will probably hang despite the available data still present in the file input buffer; meanwhile the remote peer might be expecting a response based on the data it already sent. The reason for this is that edge-triggered mode delivers events only when changes occur on the monitored file descriptor. So, in step 5 the caller might end up waiting for some data that is already present inside the input buffer. In the above example, an event on rfd will be generated because of the write done in 2 and the event is consumed in 3. Since the read operation done in 4 does not consume the whole buffer data, the call to epoll_wait(2) done in step 5 might block indefinitely.
An application that employs the EPOLLET flag should use nonblocking file descriptors to avoid having a blocking read or write starve a task that is handling multiple file descriptors. The suggested way to use epoll as an edge-triggered (EPOLLET) interface is as follows:
- with nonblocking file descriptors; and
- by waiting for an event only after read(2) or write(2) return EAGAIN.
By contrast, when used as a level-triggered interface (the default, when EPOLLET is not specified), epoll is simply a faster poll(2), and can be used wherever the latter is used since it shares the same semantics.
Since even with edge-triggered epoll, multiple events can be generated upon receipt of multiple chunks of data, the caller has the option to specify the EPOLLONESHOT flag, to tell epoll to disable the associated file descriptor after the receipt of an event with epoll_wait(2). When the EPOLLONESHOT flag is specified, it is the caller’s responsibility to rearm the file descriptor using epoll_ctl(2) with EPOLL_CTL_MOD.
If multiple threads (or processes, if child processes have inherited the epoll file descriptor across fork(2)) are blocked in epoll_wait(2) waiting on the same epoll file descriptor and a file descriptor in the interest list that is marked for edge-triggered (EPOLLET) notification becomes ready, just one of the threads (or processes) is awoken from epoll_wait(2). This provides a useful optimization for avoiding “thundering herd” wake-ups in some scenarios.
For a EPOLLIN event, the LT mode allow you to receieve the data in multiple times since the EPOLLIN event is always triggered whenever the data in the buffer is available. However, with the ET mode, the EPOLLIN event of epoll_fd is only triggered once and you have to receieve the data in the buffer within the only one time.
For a EPOLLOUT event, in the LT mode the server epoll_fd will always be triggered with the EPOLLOUT event since the client fd is always writable. So the EPOLLOUT event will be continually triggered and this is a waste of CPU. With the ET mode the EPOLLOUT event of the epoll_fd will be triggered only once whether the client fd is writable or not.
So in conclusion, you can always use the LT mode for the epoll event and this is actually the default mode of epoll event. However, if you want to optimize the performance with less times of triggered, you can use the ET mode. For example, the EPOLLOUT event for the accept returned fd.
The follwoing code will show the difference between the LT and ET mode.
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <bits/socket.h>
#include <bits/sockaddr.h>
#include <netinet/in.h>
#include <sys/select.h>
#include <poll.h>
#include <sys/epoll.h>
#include <sys/time.h>
#include <sys/types.h>
#include <errno.h>
void serverEpoll() {
int i, listenfd, connfd, epollfd;
int nready, time = -1;
ssize_t n;
const int MAX_LEN = 1024;
char buf;
socklen_t clilen;
struct sockaddr_in cliaddr, servaddr;
struct epoll_event events[MAX_LEN], listenEvent, clientEvent;
listenfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(8080);
bind(listenfd, (struct sockaddr*) &servaddr, sizeof(servaddr));
listen(listenfd, MAX_LEN);
epollfd = epoll_create1(0);
if (epollfd < 0) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
listenEvent.data.fd = listenfd;
listenEvent.events = EPOLLIN;
//listenEvent.events |= EPOLLET;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listenfd, &listenEvent) == -1) {
perror("epoll_ctl: listnfd");
exit(EXIT_FAILURE);
};
for (;;) {
nready = epoll_wait(epollfd, events, MAX_LEN, time);
if (nready == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (i = 0; i < nready; i++) {
if (events[i].data.fd == listenfd) {
clilen = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr*)&cliaddr, &clilen);
if (connfd == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
printf("The clientd %d start the connection\n", connfd);
clientEvent.data.fd = connfd;
clientEvent.events = EPOLLIN;
/* The code below will change teh events from LT mode to ET mode.
And you can use this code to show the difference between the
LT and ET mode.
*/
//clientEvent.events |= EPOLLET;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, connfd, &clientEvent) == -1) {
perror("epoll_ctl: connfd");
exit(EXIT_FAILURE);
};
}
else {
n = recv(events[i].data.fd, &buf, 1, 0);
if (n <= 0) {
printf("The clientd %d close the connection\n", events[i].data.fd);
epoll_ctl(epollfd, EPOLL_CTL_DEL, events[i].data.fd, NULL);
close(events[i].data.fd);
}
else {
printf("\nThe client fd is %d. The size of buffer is %ld and the content of buffer is \n%c\n", events[i].data.fd, n, buf);
}
}
}
}
}
int main(int argc, char* argv[]) {
//server0();
//serverSelect();
//serverPoll();
serverEpoll();
return 0;
}
As the code above shows, I design the server to receive only one character from the client and print it to the screen every time the EPOLLIN event is triggered. For example, suppose that there is a client send “1234” to the server. If I use the LT mode, the server will always be triggered with the EPOLLIN event with the connected fd of the client whenever the string in the buffer is available. So the server will continuously print the letter “1”, “2”, “3”, and “4”. However, if I use the ET mode(uncomment the code I wrote above), the server will be triggered once when the client send “1234”. The server only receive the letter “1” and can’t receive the remaining letters unless the EPOLLIN event of the client connected fd is triggered again.