We begin by clarifying some important points about relational queries. The inputs and outputs of a query are relations. A query is evaluated using instances of each input relation and it produces an instance of the output relation.
We present a number of sample queries using the following schema:
Sailors(sid: integer, sname: string, rating: integer, age: real)
Boats(bid: integer, bname: string, colot: string)
Reserves (sid: integer, bid: integer, day: date)

Relational Algebra
Selectin and Projection
Relational algebra includes operators to select rows from a relation $(\sigma)$ and to project columns $(\pi)$.
The selection operator $(\sigma)$ specifies the tuples to retain through a selection condition.
The projection operator $(\pi)$ allows us to extract columns from a relation.
Set Operations
The following standard operations on sets are also available in relational algebra: $\text { union }(\cup) \text {, intersection }(\cap) \text {, set-difference }(-), \text { and cross-product }(\times) \text {. }$
- Union: $R \cup S$ returns a relation instance containing all tuples that occur in either relation instance R or relation instance S (or both). R and S must be union-compatible, and the schema of the result is defined to be identical to the schema of R. Two relation instances are said to be union-compatible if the following conditions hold: they have the same number of the fields, and corresponding fields, taken in order from left to right, have the same domains. Note that field names are not used in defining union-compatibility. for convenience, we will assume that the fields of $R \cup S$ inherit names from R, if the fields of R have names. (This assumption is implicit in defining the schema of $R \cup S$ to be identical to the schema of R, as stated earlier.)
- Intersection: $R \cap S$ returns a relation instance containing all tuples that occur in both R and S. The relations R and S must be union-compatible, and the schema of the result is defined to be identical to the schema of R.
- Set-difference: R - S returns a relation instance containing all tuples that occur in R but not in S. The relations R and S must be union-compatible, and the schema of the result is defined to be identical to the schema of R.
- Cross-product: $R \times S$ returns a relation instance whose schema contains all the fields of R (in the same order as they appear in R) followed by all the fields of S (in the same order as they appear in S). The result of $R \times S$ contains one tuple (r, s) (the concatenation of tuples r and s) for each pair of tuples $r \in R$, $s \in S$. The cross-product opertion is sometimes called Cartesian product.
We use the convention that the fields of $R \times S$ inherit names from the corresponding fields of R and S. It is possible for both R and S to contain one or more fields having the same name; this situation creates a naming conflict. The corresponding fields in $R \times S$ are unnamed and are referred to solely by position.
Joins
The join operation is one of the most useful operations in relational algebra and the most commonly used way to combine information from two or more relations. Although a join can be defined as a cross-product followed by selections and projections, joins arise much more frequently in practice than plain cross-products. Further, the result of a cross-product is typically much larger than the result of a join, and it is very important to recognize joins and implement them without materializing the underlying cross-product (by applying the selections and projections ‘on-the-fly’). For these reasons, joins have received a lot of attention, and there are several variants of the join operation.
Condition Joins
The most general version of the join operation accepts a join condition c and a pair of relation instances as arguments and returns a relation instance. The operation is defined as follows:
$R \bowtie_{c} S=\sigma_{c}(R \times S)$
Thus $\bowtie$ is defined to be a cross-product followed by a selection. Note that the condition c can (and typically does) refer to attributes of both R and S. The reference to an attribute of a relation, say, R, can be by position (of the form R.i) or by name (of the form R.name).
Equijoin
A common special case of the join operation $R \bowtie S$ is when the join condition consists solely of equalities of the form R.name1 = S.name2, that is, equalities between two fields in R and S. In this case, obviously, there is some redundancy in retaining both attributes in the result. For join conditions that contain only such equalities, the join operation is refined by doing an additional projection in which S.name2 is dropped. The join operation with this refinement is called equijoin.
The schema of the result of an equijoin contains the fields of R (with the same names and domains as in R) followed by the fields of S that do not appear in the join conditions. If this set of fields in the result relation includes two fields that inherit the same name from R and S, they are unnamed in the result relation.
Natural Join
A further special case of the join operation $R \bowtie S$ is an equijoin in which equalities are specified on all fields having the same name in R and S. In this case, we can simply omit the join condition; the default is that the join condition is a collection of equalities on all common fields. We call this special case a natural join, and it has the nice property that the result is guaranteed not to have two fields with the same name.
The equijoin expression $S1 \bowtie_{R . \text { sid }=\text { S.sid }} R 1$ is actually a natural join and can simply be denoted as $S1 \bowtie R1$, since the only common field is sid. If the two relations have no attributes in common, $S1 \bowtie R1$ is simply the cross-product.
Division
For each x value in (the first column of) A, consider the set of y values that appear in (the second field of) tuples of A with that x value. If this set contains (all y values in) B, the x value is in the result of A / B. As figure 4.14 shows:
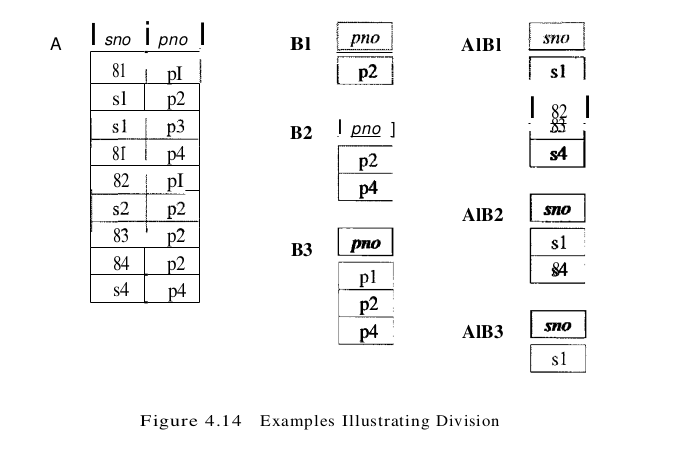
Relational Calculus
Relational calculus has had a big influence on the design of commercial query languages such as SQL and, especially, Query-by-Example (QBE).
The variant of the calculus we present in detail is called the tuple relational calculus (TRC). Variables in TRC take on tuples as values. In another variant, called the domain relational calculus (DRC), the variables range over field values. TRC has had more of an influence on SQL, while DRC has strongly influenced QBE.
Tuple Relational Calculus
A tuple variable is a variable that takes on tuples of a particular relation schema as values. That is, every value assigned to a given tuple variable has the same number and type of fields. A tuple relational calculus query has the form ${T \mid p(T)}$, where T is a tuple variable and p(T) denotes a formula that describes T; The result of this query is the set of all tuples t for which the formula p(T) evaluates to true with T = t. The language for writing formulas p(T) is thus at the heart of TRC and essentially a simple subset of first-order logic. As a simple example, consider the following query.
Find all sailors with a rating above 7.
${S \mid S \in Sailors \wedge S.rating >7}$
When this query is evaluated on an instance of the Sailors relation, the tuple variable S is instantiated successively with each tuple, and the test S.rating> 7 is applied.
We now define these concepts formally, beginning with the notion of a formula. Let Rel be a relation name, R and S be tuple variables, a be an attribute of R, and b be an attribute of S. Let op denote an operator in the set {$>, <, =, \leq, \geq, \neq$}. An atomic formula is one of the following:
- $R \in Rel$
- R.a op S.b
- R.a op constant, or constant op R.a
A formula is recursively defined to be one of the following, where p and q are themselves formulas and p(R) denotes a formula in which the variable R appears:
- any atomic formula
- $\neg p, P \wedge q, P \vee q, \text { or } p \Rightarrow q$
- $\exists R(p(R))$, where R is a tuple variable.
- $\forall R(p(R))$, where R is a tuple variable.
In the last two clauses, the quantifiers $\exist$ and $\forall$ if are said to bind the variable R. A variable is said to be free in a formula or subformula (a formula contained in a larger formula) if the (sub)formula does not contain an occurrence of a quantifier that binds it.
The answer to a TRC query {T | p(T)}, as noted earlier, is the set of all tuples t for which the formula p(T) evaluates to true with variable T assigned the tuple value t. To complete this definition, we must state which assignments of tuple values to the free variables in a formula make the formula evaluate to true.
Domain Relational Calculus
A domain variable is a variable that ranges over the values in the domain of some attribute (e.g., the variable can be assigned an integer if it appears in an attribute whose domain is the set of integers). A DRC query has the form ${\left(X_I, X_2, \ldots, X_{n}\right) \mid P\left(\left(X_1, X_2, \ldots, X_{n}\right)\right)}$, where each $X_i$ is either a domain variable or a constant and $P\left(\left(X_1, X_2, \ldots, X_{n}\right)\right)$ denotes a DRC formula whose only free variables are the variables among the $X_i, 1 \leq i \leq n$. The result of this query is the set of all tuples $(X_1, X_2, … , X_n )$ for which the formula evaluates to true.
A DRC formula is defined in a manner very similar to the definition of a TRC formula. The main difference is that the variables are now domain variables. Let op denote an operator in the set {$>, <, =, \leq, \geq, \neq$} and let X and Y be domain variables. An atomic formula in DRC is one of the following:
- $\left(X_1, X_2, \ldots, X_{n}\right)$ $\in$ Rel, where Rel is a relation with $n$ attributes; each $X_i, \quad 1 \leq i \leq n$ is either a variable or a constant
- X op Y
- X op constant, or constant op X
A formula is recursively defined to be one of the following, where P and q are themselves formulas and p(X) denotes a formula in which the variable X appears:
- any atomic formula
- $\neg p, P \wedge q, P \vee q$, or $p \Rightarrow q$
- $\exists X(p(X))$, where $X$ is a domain variable
- $\forall X(p(X))$, where $X$ is a domain variable