- 2PL, Serializability and Recoverability
- Introduction to Lock Management
- Lock Conversions
- Dealing With Deadlocks
- Specialized Locking Techniques
- Concurrency Control Without Locking
2PL, Serializability and Recoverability
In this section, we consider how locking protocols guarantee some important properties of schedules; namely, serializability and recoverability. Two schedules are said to be conflict equivalent if they involve the (same set of) actions of the same transactions and they order every pair of conflicting actions of two committed transactions in the same way.
Two actions conflict if they operate on the same data object and at least one of them is a write. The outcome of a schedule depends only on the order of conflicting operations; we can interchange any pair of nonconflicting operations without altering the effect of the schedule on the database. If two schedules are conflict equivalent, it is easy to see that they have the same effect on a database. Indeed, because they order all pairs of conflicting operations in the same way, we can obtain one of them from the other by repeatedly swapping pairs of nonconflicting actions, that is, by swapping pairs of actions whose relative order does not alter the outcome.
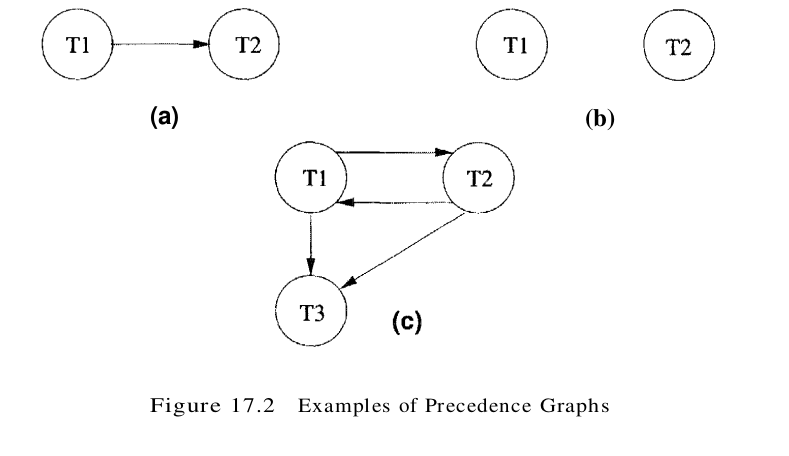
A schedule is conflict serializable if it is conflict equivalent to some serial schedule. Every conflict serializable schedule is serializable, if we assume that the set of items in the database does not grow or shrink; that is, values can be modified but items are not added or deleted. We make this assumption for now. However, some serializable schedules are not conflict serializable, as illustrated in Figure 17.1. This schedule is equivalent to executing the transactions serially in the order T1, T2, T3, but it is not conflict equivalent to this serial schedule because the writes of T1 and T2 are ordered differently. It is useful to capture all potential conflicts between the transactions in a schedule in a precedence graph, also called a serializability graph. The precedence graph for a schedule S contains:
- A node for each committed transaction in S.
- An arc from Ti to Tj if an action of Ti precedes and conflicts with one of Tj’s actions.

The Strict 2PL protocol allows only conflict serializable schedules, as is seen from the following two results:
- A schedule S’ is conflict serializable if and only if its precedence graph is acyclic. (An equivalent serial schedule in this case is given by any topological sort over fhe precedence graph.)
- Strict 2PL ensures that the precedence graph for any schedule that it allows is acyclic.
A widely studied variant of Strict 2PL, called Two-Phase Locking (2PL), relaxes the second rule of Strict 2PL to allow transactions to release locks before the end, that is, before the commit or abort action. For 2PL, the second rule is replaced by the following rule:
- A transaction cannot request additional locks once it releases any lock.
It can be shown that even nonstrict 2PL ensures acyclicity of the precedence graph and therefore allows only conflict serializable schedules. Intuitively, an equivalent serial order of transactions is given by the order in which transactions enter their shrinking phase: If T2 reads or writes an object written by T1, T1 must have released its lock on the object before T2 requested a lock on this object. Thus, T1 precedes T2. (A similar argument shows that T1 precedes T2 if T2 writes an object previously read by T1. A formal proof of the claim would have to show that there is no cycle of transactions that ‘precede’ each other by this argurnent.)
A schedule is said to be strict if a value written by a transaction T is not read or overwritten by other transactions until T either aborts or commits. Strict schedules are recoverable, do not require cascading aborts, and actions of aborted transactions can be undone by restoring the original values of modified objects. Strict 2PL improves on 2PL by guaranteeing that every allowed schedule is strict in addition to being conflict serializable. The reason is that when a transaction T writes an object under Strict 2PL, it holds the (exclusive) lock until it commits or aborts. Thus, no other transaction can see or modify this object until T is complete.
Conflict serializability is sufficient but not necessary for serializability. A more general sufficient condition is view serializability. Two schedules S1 and S2 over the same set of transactions – any transaction that appears in either S1 or S2 must also appear in the other are view equivalent under these conditions:
- If Ti reads the initial value of object A in S1, it must also read the initial value of A in S2.
- If Ti reads a value of A written by Tj in S1, it must also read the value of A written by Tj in S2.
- For each data object A, the transaction (if any) that performs the final write on A in S1 must also perform the final write on A in S2.
A schedule is view serializable if it is view equivalent to same serial schedule. Every conflict serializable schedule is view serializable, although the converse is not true. For example, the schedule shown in Figure 17.1 is view serializable, although it is not conflict serializable. Incidentally, note that this example contains blind writes. This is not a coincidence; it can be shown that any view serializable schedule that is not conflict serializable contains a blind write. As we shown previously, efficient locking protocols allow us to ensure that only conflict serializable schedules are allowed. Enforcing or testing view serializability turns out to be much more expensive, and the concept therefore has little practical use, although it increases our understanding of serializability.
Introduction to Lock Management
The part of the DBMS that keeps track of the locks issued to transactions is called the lock manager. The lock manager maintains a lock table, which is a hash table with the data object identifier as the key. The DBMS also maintains a descriptive entry for each transaction in a transaction table, and among other things, the entry contains a pointer to a list of locks held by the transaction. This list is checked before requesting a lock, to ensure that a transaction does not request the same lock twice.
A lock table entry for an object – which can be a page, a record, and so on, depending on the DBMS-contains the following information: the number of transactions currently holding a lock on the object (this can be more than one if the object is locked in shared mode), the nature of the lock (shared or exclusive), and a pointer to a queue of lock requests.
Lock Conversions
A transaction may need to acquire an exclusive lock on an object for which it already holds a shared lock. For example, a SQL update statement could result in shared locks being set on each row in a table. If a row satisfies the condition (in the WHERE clause) for being updated, an exclusive lock must be obtained for that row. Such a lock upgrade request must be handled specially by granting the exclusive lock immediately if no other transaction holds a shared lock on the object and inserting the request at the front of the queue otherwise. The rationale for favoring the transaction thus is that it already holds a shared lock on the object and queuing it behind. Another transaction that wants an exclusive lock on the same object causes both a deadlock. Unfortunately, while favoring lock upgrades helps, it does not prevent deadlocks caused by two conflicting upgrade requests. For example, if two transactions that hold a shared lock on an object both request an upgrade to an exclusive lock, this leads to a deadlock.
A better approach is to avoid the need for lock upgrades altogether by obtaining exclusive locks initially, and downgrading to a shared lock once it is clear that this is sufficient. In our example of an SQL update statement, rows in a table are locked in exclusive mode first. If a row does not satisfy the condition for being updated, the lock on the row is dnwngraded to a shared lock. Does the downgrade approach violate the 2PL requirernent? On the surface, it does, because downgrading reduces the locking privileges held by a transaction, and the transaction may go on to acquire other locks. However, this is a special case, because the transaction did nothing but read the object that it downgraded, even though it conservatively obtained an exclusive lock. We can safely expand our definition of 2PL to allow lock downgrades in the growing phase, provided that the transaction has not modified the object. The downgrade approach reduces concurrency by obtaining write locks in some cases where they are not required. On the whole, however, it improves throughput by reducing deadlocks. This approach is therefore widely used in current commercial systems.
Concurrency can be increased by introducing a new kind of lock, called an update lock, that is compatible with shared locks but not other update and exclusive locks. By setting an update lock initially, rather than exclusive locks, we prevent conflicts with other read operations. Once we are sure we need not update the object, we can downgrade to a shared lock. If we need to update the object, we must first upgrade to an exclusive lock. This upgrade does not lead to a deadlock because no other transaction can have an update or exclusive lock on the object.
Dealing With Deadlocks
Deadlocks tend to be rare and typically involve very few transactions. In practice, therefore, database systems periodically check for deadlocks. When a transaction Ti is suspended because a lock that it requests cannot be granted, it must wait until all transactions Tj that currently hold conflicting locks release them. The lock manager maintains a structure called a waits-for graph to detect deadlock cycles. The nodes correspond to active transactions, and there is an arc from Ti to Tj if (and only if)Ti is waiting for Tj to release a lock. The lock manager adds edges to this graph when it queues lock requests and removes edges when it grants lock requests. Consider the schedule shown in Figure 17.3. The last step, shown below the line, creates a cycle in the waits-for graph. Figure 17.4 shows the waits-for graph before and after this step.

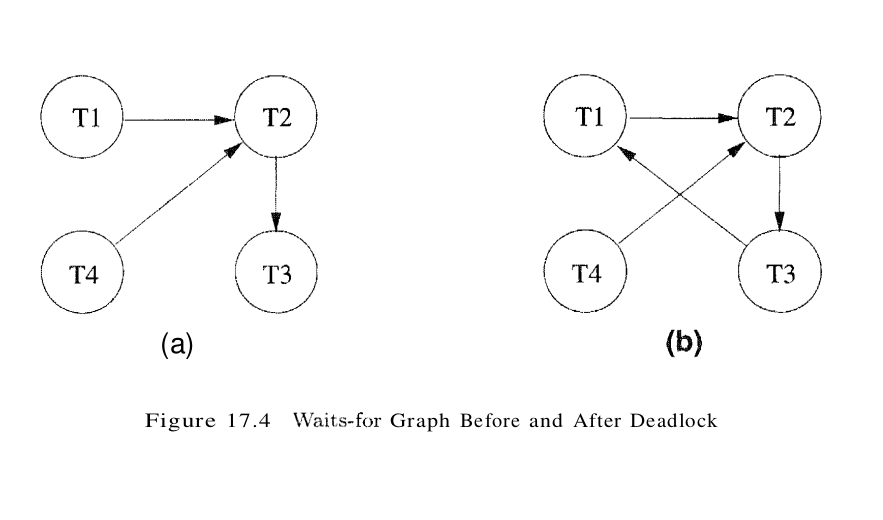
Observe that the waits-for graph describes all active transactions, some of which eventually abort. If there is an edge from Ti to Tj in the waits-for graph, and both Ti and Tj eventually commit, there is an edge in the opposite direction (from Tj to Ti) in the precedence graph (which involves only committed transactions). The waits-for graph is periodically checked for cycles, which indicate deadlock. A deadlock is resolved by aborting a transaction that is on a cycle and releasing its locks; this action allows some of the waiting transactions to proceed. The choice of which transaction to abort can be made using several criteria: the one with the fewest locks, the one that has done the least work, the one that is farthest from completion, and so all. Further, a transaction might have been repeatedly restarted; if so, it should eventually be favored during deadlock detection and allowed to complete. A simple alternative to maintaining a waits-for graph is to identify deadlocks through a timeout mechanism: If a transaction has been waiting too long for a lock, we assume that it is in a deadlock cycle and abort it.
Deadlock Prevention
Empirical results indicate that deadlocks are relatively infrequent, and detection-based schemes work well in practice. However, if there is a high level of contention for locks and therefore an increased likelihood of deadlocks, prevention-based schemes could perform better. We can prevent deadlocks by giving each transaction a priority and ensuring that lower-priority transactions are not allowed to wait for higher-priority transactions (or vice versa). One way to assign priorities is to give each transaction a timestamp when it starts up. The lower the timestamp, the higher is the transaction’s priority; that is, the oldest transaction has the highest priority. If a transaction Ti requests a lock and transaction Tj holds a conflicting lock, the lock lnanager can use one of the following two policies:
- Wait-die: If Ti has higher priority, it is allowed to wait; otherwise, it is aborted.
- Wound-wait: If Ti has higher priority, abort Tj; otherwise, Ti waits.
In the wait-die scheme, lower-priority transactions can never wait for higher-priority transactions. In the wound-wait scheme, higher-priority transactions never wait for lower-priority transactions. In either ease, no deadlock cycle develops.
A subtle point is that we must also ensure that no transaction is perennially aborted because it never has a sufficiently high priority. (Note that, in both schemes, the higher-priority transaction is never aborted.) When a transaction is aborted and restarted, it should be given the same timestamp it had originally. Reissuing timestamps in this way ensures that each transaction will eventually become the oldest transaction, and therefore the one with the highest priority, and will get all the locks it requires. The wait-die scheme is nonpreemptive; only a transaction requesting a lock can be aborted. As a transaction grows older (and its priority increases), it tends to wait for more and more younger transactions. A younger transaction that conflicts with an older transaction may be repeatedly aborted (a disadvantage with respect to wound-wait), but on the other hand, a transaction that has all the locks it needs is never aborted for deadlock reasons (an advantage with respect to wound-wait, which is preemptive). A variant of 2PL, called Conservative 2PL, can also prevent deadlocks. Under Conservative 2PL, a transaction obtains all the locks it will ever need when it begins, or blocks waiting for these locks to become available. This scheme ensures that there will be no deadlocks, and, perhaps more important, that a transaction that already holds some locks will not block waiting for other locks. If lock contention is heavy, Conservative 2PL can reduce the time that locks are held on average, because transactions that hold locks are never blocked. The trade-off is that a transaction acquires locks earlier, and if lock contention is low, locks are held longer under Conservative 2PL. From a practical perspective, it is hard to know exactly what locks are needed ahead of time, and this approach leads to setting more locks than necessary. It also has higher overhead for setting locks because a transaction has to release all locks and try to obtain thern all over if it fails to obtain even one lock that it needs. This approach is therefore not used in practice.
Specialized Locking Techniques
Thus far we have treated a database as a fixed collection of independent data objects in our presentation of locking protocols. We now relax each of these restrictions and discuss the consequences. If the collection of database objects is not fixed, but can grow and shrink through the insertion and deletion of objects, we must deal with a subtle complication known as the phantom problem.
Dynamic Databases and the Phantom Problem
Consider the following example: transaction T1 scans the Sailors relation to find the oldest sailor for each of the rating levels 1 and 2. First, T1 identifies and locks all pages (assuming that page-level locks are set) containing sailors with rating 1 and then finds the age of the oldest sailor, which is, say, 71. Next, transaction T2 inserts a new sailor with rating 1 and age 96. Observe that this new Sailors record can be inserted onto a page that does not contain other sailors with rating 1; thus, an exclusive lock on this page does not conflict with any of the locks held by T1. T2 also locks the page containing the oldest sailor with rating 2 and deletes this sailor (whose age is, say, 80). T2 then commits and releases its locks. Finally, transaction T1 identifies and locks pages containing (all remaining) sailors with rating 2 and finds the age of the oldest such sailor, which is, say, 63. The result of the interleaved execution is that ages 71 and 63 are printed in response to the query. If T1 had run first, then T2, we would have gotten the ages 71 and 80; if T2 had run first, then T1, we would have gotten the ages 96 and 63. Thus, the result of the interleaved execution is not identical to any serial exection of T1 and T2, even though both transactions follow Strict 2PL and commit. The problem is that T1 assumes that the pages it has locked include all pages containing Sailors records with rating 1, and this assumption is violated when T2 inserts a new such sailor on a different page. The flaw is not in the Strict 2PL protocol. Rather, it is in T1’s implicit assumption that it has locked the set of all Sailors records with rating value 1. T1’s semantics requires it to identify all such records, but locking pages that contain such records at a given time does not prevent new “phantom” records from being added on other pages. T1 has threfore not locked the set of desired Sailors records.
Strict 2PL guarantees conflict serializability; indeed, there are no cycles in the precedence graph for this example because conflicts are defined with respect to objects (in this example, pages) read/written by the transactions. However, because the set of objects that should have been locked by T1 was altered by the actions of T2, the outcome of the schedule differed from the outcome of any serial execution. This example brings out an important point about conflict serializability: If new items are added to the database, conflict serializability does not guarantee serializability. A closer look at how a transaction identifies pages containing Sailors records with rating 1 suggests how the problem can be handled:
- If there is no index and all pages in the file must be scanned, T1 must somehow ensure that no new pages are added to the file, in addition to locking all existing pages.
- If there is an index on the rating field, T1 can obtain a lock on the index page, assuming that physical locking is done at the page level that contains a data entry with rating = 1. If there are no such data entries, that is, no records with this rating value, the page that would contain a data entry for rating = 1 is locked to prevent such a record from being inserted. Any transaction that tries to insert a record with rating = 1 into the Sailors relation must insert a data entry pointing to the new record into this index page and is blocked until T1 releases its locks. This technique is called index locking.
Both techniques effectively give T1 a lock on the set of Sailors records with rating = 1: Each existing record with rating = 1 is protected from changes by other transactions, and additionally, new records with rating = 1 cannot be inserted. An independent issue is how transaction T1 can efficiently identify and lock the index page containing rating = 1. We discuss this issue for the case of tree-structured indexes. We note that index locking is a special case of a more general concept called predicate locking. In our example, the lock on the index page implicitly locked all Sailors records that satisfy the logical predicate rating = 1. More generally, we can support implicit locking of all records that match an arbitrary predicate. General predicate locking is expensive to implement and therefore not commonly used.
Concurrency Control in B+ Trees
A straightforward approach to concurrency control for B+ trees and ISAM indexes is to ignore the index structure, treat each page as a data object, and use strict version of 2PL. This simplistic locking strategy would lead to very high lock contention in the higher levels of the tree because every tree search begins at the root and proceeds along some path to a leaf node. Fortunately, much more efficient locking protocols that exploit the hierarchical structure of a tree index are known to reduce the locking overhead while ensuring serializability and recoverability. We discuss some of these approaches briefly, concentrating on the search and insert operations.
Two observations provide the necessary insight:
- The higher levels of the tree only direct searches. All the ‘real’ data is in the leaf levels (in the format of one of the three alternatives for data entries).
- For inserts, a node must be locked (in exclusive mode, of course) only if a split can propagate up to it from the modified leaf.
Searches should obtain shared locks on nodes, starting at the root and proceeding along a path to the desired leaf. The first observation suggests that a lock on a node can be released as soon as a lock on a child node is obtained, because searches never go back up the tree. A conservative locking strategy for inserts would be to obtain exclusive locks on all nodes as we go down from the root to the leaf node to be modified, because splits can propagate all the way from a leaf to the root. However, once we lock the child of a node, the lock on the node is required only in the event that a split propagates back to it. In particular, if the child of this node (on the path to the modified leaf) is not full when it is locked, any split that propagates up to the child can be resolved at the child, and does not propagate further to the current node. Therefore, when we lock a child node, we can release the lock on the parent if the child is not full. The locks held thus by an insert force any other transaction following the same path to wait at the earliest point (i.e., the node nearest the root) that might be affected by the insert. The technique of locking a child node and (if possible) releasing the lock on the parent is called lock-coupling, or crabbing (think of how a crab walks, and compare it to how we proceed down a tree, alternately releasing a lock on a parent and setting a lock on a child). We illustrate B+ tree locking using the tree in Figure 17.5.

To search for data entry 38*, a transaction Ti must obtain an S lock on node A, read the contents and determine that it needs to examine node B, obtain an S lock on node B and release the lock on A, then obtain an S lock on node C and release the lock on B, then obtain an S lock on node D and release the lock on C. Ti always maintains a lock on one node in the path, to force new transactions that want to read or modify nodes on the same path to wait until the current transaction is done.
If transaction Tj wants to delete 38*, for example, it must also traverse the path from the root to node D and is forced to wait until Ti is done.
Of course, if some transaction Tk holds a lock on, say, node C before Ti reaches this node, Ti is similarly forced to wait for Tk to complete. To insert data entry 45*, a transaction must obtain an S lock on node A, obtain an S lock on node B and release the lock on A, then obtain an S lock on node C (observe that the lock on B is not released, because C is full), then obtain an X lock on node E and release the locks on C and then B. Because node E has space for the new entry, the insert is accomplished by modifying this node.
In contrast, consider the insertion of data entry 25*. Proceeding as for the insert of 45*, we obtain an X lock on node H. Unfortunately, this node is full and must be split. Splitting H requires that we also modify the parent, node F, but the transaction has only an S lock on F. Thus, it must request an upgrade of this lock to an X lock. If no other transaction holds an S lock on F, the upgrade is granted, and since F has space, the split does not propagate further and the insertion of 25* can proceed (by splitting H and locking G to modify the sibling pointer in I to point to the newly created node). However, if another transaction holds an S lock on node F, the first transaction is suspended until this transaction releases its S lock.
Observe that if another transaction holds an S lock on F and also wants to access node H, we have a deadlock because the first transaction has an X lock on H. The preceding example also illustrates an interesting point about sibling pointers: When we split leaf node H, the new node must be added to the left of I, since otherwise the node whose sibling pointer is to be changed would be node I, which has a different parent. To modify a sibling pointer on I, we would have to lock its parent, node C (and possibly ancestors of C, in order to lock C).
Except for the locks on intermediate nodes that we indicated could be released early, some variant of 2PL must be used to govern when locks can be released, to ensure serializability and recoverability. This approach improves considerably on the naive use of 2PL, but several exclusive locks are still set unnecessarily and, although they are quickly released, affect performance substantially. One way to improve performance is for inserts to obtain shared locks instead of exclusive locks, except for the leaf, which is locked in exclusive mode. In the vast majority of cases, a split is not required and this approach works very well. If the leaf is full, however, we must upgrade from shared locks to exclusive locks for all nodes to which the split propagates. Note that such lock upgrade requests can also lead to deadlocks. The tree locking ideas that we describe illustrate the potential for efficient locking protocols in this very important special case, but they are not the current state of the art.
Multiple-Granularity Locking
Another specialized locking strategy, called multiple-granularity locking, allows us to efficiently set locks on objects that contain other objects.
For instance, a database contains several files, a file is a collection of pages, and a page is a collection of records. A transaction that expects to access most of the pages in a file should probably set a lock on the entire file, rather than locking individual pages (or reeords) when it needs them. Doing so reduces the locking overhead considerably. On the other hand, other transactions that require access to parts of the file – even parts not needed by this transaction are blocked. If a transaction accesses relatively few pages of the file, it is better to lock only those pages. Similarly, if a transaction accesses several records on a page, it should lock the entire page, and if it accesses just a few records, it should lock just those records. The question to be addressed is how a lock manager can efficiently ensure that a page, for example, is not locked by a transaction while another transaction holds a conflicting lock on the file containing the page (and therefore, implicitly, on the page).
The idea is to exploit the hierarchical nature of the contains relationship. A database contains a set of files, each file contains a set of pages, and each page contains a set of records. This containment hierarchy can be thought of as a tree of objects, where each node contains all its children. (The approach can easily be extended to cover hierarchies that are not trees, but we do not discuss this extension.) A lock on a node locks that node and, implicitly, all its descendants. (Note that this interpretation of a lock is very different from B+ tree locking, where locking a node does not lock any descendants implicitly.) In addition to shared (S) and exclusive (X) locks, multiple-granularity locking protocols also use two new kinds of locks, called intention shared (IS) and intention exclusive (IX) locks. IS locks conflict only with X locks. IX locks conflict with S and X locks. To lock a node in S (respectively, X) mode, a transaction must first lock all its ancestors in IS (respectively, IX) mode. Thus, if a transaction locks a node in S mode, no other transaction can have locked any ancestor in X mode; similarly, if a transaction locks a node in X mode, no other transaction can have locked any ancestor in S or X mode. This ensures that no other transaction holds a lock on an ancestor that conflicts with the requested S or X lock on the node.
A common situation is that a transaction needs to read an entire file and modify a few of the records in it; that is, it needs an S lock on the file and an IX lock so that it can subsequently lock some of the contained objects in X mode. It is useful to define a new kind of lock, called an SIX lock, that is logically equivalent to holding an S lock and an IX lock. A transaction can obtain a single SIX lock (which conflicts with any lock that conflicts with either S or IX) instead of an S lock and an IX lock.
A subtle point is that locks must be released in leaf-to-root order for this protocol to work correctly. To see this, consider what happens when a transaction Ti locks all nodes on a path from the root (corresponding to the entire database) to the node corresponding to some page p in IS mode, locks p in S mode, and then releases the lock on the root node. Another transaction Tj could now obtain an X lock on the root. This lock implicitly gives Tj an X lock on page p, which conflicts with the S lock currently held by Ti.
Multiple-granularity locking must be used with 2PL to ensure serializability. The 2PL protocol dictates when locks can be released. At that time, locks obtained using multiple-granularity locking can be released and must be released in leaf-to-root order. Finally, there is the question of how to decide what granularity of locking is appropriate for a given transaction. One approach is to begin by obtaining fine granularity locks (e.g., at the record level) and, after the transaction requests a certain number of locks at that granularity, to start obtaining locks at the next higher granularity (e.g., at the page level). This procedure is called lock escalation.
Concurrency Control Without Locking
Optimistic Concurrency Control
Locking protocols take a pessimistic approach to conflicts between transactions and use either transaction abort or blocking to resolve conflicts. In a system with relatively light contention for data objects, the overhead of obtaining locks and following a locking protocol must nonetheless be paid. In optimistic concurrency control, the basic premise is that most transactions do not conflict with other transactions, and the idea is to be as permissive as possible in allowing transactions to execute. Transactions proceed in three phases:
- Read: The transaction executes, reading values from the database and writing to a private workspace.
- Validation: If the transaction decides that it wants to commit, the DBMS checks whether the transaction could possibly have conflicted with any other concurrently executing transaction. If there is a possible conflict, the transaction is aborted; its private workspace is cleared and it is restarted.
- Write: If validation determines that there are no possible conflicts, the changes to data objects made by the transaction in its private workspace are copied into the database.
If, indeed, there are few conflicts, and validation can be done efficiently, this approach should lead to better performance than locking. If there are many conflicts, the cost of repeatedly restarting transactions (thereby wasting the work they’ve done) hurts performance significantly. Each transaction Ti is assigned a timestamp TS(Ti) at the beginning of its validation phase, and the validation criterion checks whether the timestamp ordering of transactions is an equivalent serial order. For every pair of transactions Ti and Tj such that TS(Ti) < TS(Tj), one of the following validation conditions must hold:
- Ti completes (all three phases) before Tj begins.
- Ti completes before Tj starts its Write phase, and Ti does not write any database object read by Tj.
- Ti completes its Read phase before Tj completes its Read phase, and Ti does not write any database object that is either read or written by Tj.
To validate Tj, we must check to see that one of these conditions holds with respect to each committed transaction Ti such that TS(Ti) < TS(Tj). Each of these conditions ensures that Tj’s modifications are not visible to Ti. Further, the first condition allows Tj to see some of Ti’s changes, but clearly, they execute completely in serial order with respect to each other.
The second condition allows Tj to read objects while Ti is still modifying objects, but there is no conflict because Tj does not read any object modified by Ti. Although Tj might overwrite some objects written by Ti, all of Ti’s writes precede all of Tj’s writes.
The third condition allows Ti and Tj to write objects at the same time and thus have even more overlap in time than the second condition, but the sets of objects written by the two transactions cannot overlap. Thus, no RW, WR, or WW conflicts are possible if any of these three conditions is met.
Checking these validation criteria requires us to maintain lists of objects read and written by each transaction. Further, while one transaction is being validated, no other transaction can be allowed to commit; otherwise, the validation of the first transaction might miss conflicts with respect to the newly committed transaction. The Write phase of a validated transaction must also be completed (so that its effects are visible outside its private workspace) before other transactions can be validated.
A synchronization mechanism such as a critical section can be used to ensure that at most one transaction is in its (combined) Validation/Write phases at any time. (When a process is executing a critical section in its code, the system suspends all other processes.) Obviously, it is important to keep these phaes as short as possible in order to minimize the impact on concurrency. If copies of modified objects have to be copied from the private workspace, this can make the Write phase long.
An alternative approach (which carries the penalty of poor physical locality of objects, such as B+ tree leaf pages, that must be clustered) is to use a level of indirection. In this scheme, every object is accessed via a logical pointer, and in the Write phase, we simply switch the logical pointer to point to the version of the object in the private workspace, instead of copying the Object. Clearly, it is not the case that optimistic concurrency control has no overheads; rather, the locking overheads of lock-based approaches are replaced with the overheads of recording read-lists and write-lists for transactions, checking for conflicts, and copying changes from the private workspace. Similarly, the implicit cost of blocking in a lock-based approach is replaced by the implicit cost of the work wasted by restarted transactions.
Improved Conflict Resolution
Optimistic Concurrency Control using the three validation conditions described earlier is often overly conservative and unnecessarily aborts and restarts transactions. In particular, according to the validation conditions, Ti cannot write any object read by Tj. However, since the validation is aimed at ensuring that Ti logically executes before Tj, there is no harm if Ti writes all data items required by Tj before Tj reads them. The problem arises because we have no way to tell when Ti wrote the object (relative to Tj’s reading it) at the time we validate Tj, since all we have is the list of objects written by Ti and the list read by Tj. Such false conflicts can be alleviated by a finer-grain resolution of data conflicts, using mechanisms very similar to locking.
The basic idea is that each transaction in the Read phase tells the DBMS about items it is reading, and when a transaction Ti is committed (and its writes are accepted), the DBMS checks whether any of the items written by Ti are being read by any (yet to be validated) transaction Tj. If so, we know that Tj’s validation must eventually fail. We can either allow Ti to discover this when it is validated (the die policy) or kill it and restart it immediately (the kill policy). The details are as follows. Before reading a data item, transaction T enters an access entry in a hash table. The access entry contains the transaction id, a data object id, and a modified flag (initially set to false), and entries are hashed on the data object id. A temporary exclusive lock is obtained on the hash bucket containing the entry, and the lock is held while the read data item is copied from the database buffer into the private workspace of the transaction. During validation of T the hash buckets of all data objects accessed by T are again locked (in exclusive mode) to check if T has encountered any data conflicts. T has encountered a conflict if the modified flag is set to true in one of its access entries. (This assumes that the ‘die’ policy is being used; if the ‘kill’ policy is used, T is restarted when the flag is set to true.) If T is successfully validated, we lock the hash bucket of each object modified by T, retrieve all access entries for this object, set the modified flag to true, and release the lock on the bucket. If the ‘kill’ policy is used, the transactions that entered these access entries are restarted. We then complete T’s Write phase. It seems that the ‘kill’ policy is always better than the ‘die’ policy, because it reduces the overall response time and wasted processing. However, executing T to the end has the advantage that all of the data items required for its execution are prefetched into the database buffer, and restarted executions of T will not require disk I/O for reads. This assumes that the database buffer is large enough that prefetched pages are not replaced, and, more important, that access invariance prevails; that is, successive executions of T require the same data for execution. When T is restarted its execution time is much shorter than before because no disk I/O is required, and thus its chances of validation are higher. (Of course, if a transaction has already completed its Read phase once, subsequent conflicts should be handled using the ‘kill’ policy because all its data objects are already in the buffer pool.)
Timestamp-Based Concurrency Control
In lock-based concurrency control, conflicting actions of different transactions are ordered by the order in which locks are obtained, and the lock protocol extends this ordering on actions to transactions, thereby ensuring serializability. In optimistic concurrency control, a timestamp ordering is imposed on transactions and validation checks that all conflicting actions occurred in the same order. Timestamps can also be used in another way: Each transaction can be assigned a timestamp at startup, and we can ensure, at execution time, that if action ai of transaction Ti conflicts with action aj of transaction Tj, ai occurs before aj if TS(Ti) < TS(Tj). If an action violates this ordering, the transaction is aborted and restarted.
To implement this concurrency control scheme, every database object O is given a read timestamp RTS(O) and a write timestamp WTS(O). If transaction T wants to read object O, and TS(T) < WTS(O), the order of this read with respect to the most recent write on O would violate the timestamp order between this transaction and the writer. Therefore, T is aborted and restarted with a new, larger timestamp. If TS(T) > WTS(O), T reads O, and WTS(O) is set to the larger of RTS(O) and TS(T). (Note that a physical change – the change to RTS(O) – is written to disk and recorded in the log for recovery purposes, even on reads. This write operation is a significant overhead.) Observe that if T is restarted with the same timestamp, it is guaranteed to be aborted again, due to the same conflict. Contrast this behavior with the use of timestamps in 2PL for deadlock prevention, where transactions are restarted with the same timestamp as before to avoid repeated restarts. This shows that the two uses of timestamps are quite different and should not be confused. Next, consider what happens when transaction T wants to write object O:
- If TS(T) < RTS(O), the write action conflicts with the most recent read action of O, and T is therefore aborted and restarted.
- If TS(T) < WTS(O), a naive approach would be to abort T because its write action conflicts with the most recent write of O and is out of timestamp order. However, we can safely ignore such writes and continue. Ignoring outdated writes is called the Thomas Write Rule.
- Otherwise, T writes O and WTS(O) is set to TS(T).
The Thomas Write Rule
We now consider the justification for the Thomas Write Rule. If TS(T) < WTS(O), the current write action has, in effect, been made obsolete by the most recent write of O, which follows the current write according to the timestamp ordering. We can think of T’s write action as if it had occurred immediately before the most recent write of O and was never read by anyone. If the Thomas Write Rule is not used, that is, T is aborted in case (2), the timestamp protocol, like 2PL, allows only conflict serializable schedules. If the Thomas Write Rule is used, some schedules are permitted that are not conflict serializable, as illustrated by the schedule in Figure 17.6. Because T2’s Write follows T1’s read and precedes T1’s write of the same object, this schedule is not conflict serializable.
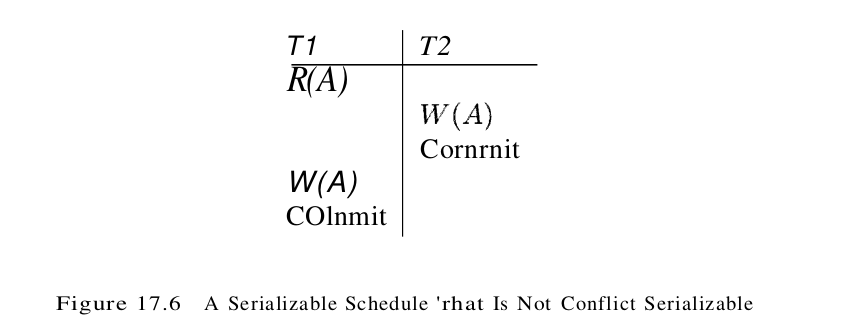
The Thomas Write Rule relies on the observation that T2’s write is never seen by any transaction and the schedule in Figure 17.6 is therefore equivalent to the serializable schedule obtained by deleting this write action, which is shown in Figure 17.7.

Recoverability
Unfortunately, the timestamp protocol just presented permits schedules that are not recoverable, as illustrated by the schedule in Figure 17.8. If TS(T1) = 1 and TS(T2) = 2, this schedule is permitted by the timestamp protocol (with or without the Thomas Write Rule). The timestamp protocol can be modified to disallow such schedules by buffering all write actions until the transaction commits. In the example, when T1 wants to write A, WTS(A) is updated to reflect this action, but the change to A. is not carried out immediately; instead, it is recorded in a private workspace, or buffer. When T2 wants to read A subsequently, its timestamp is compared with TS(A), and the read is seen to be permissible. However, T2 is blocked until T1 completes. If T1 commits, its change to A is copied from the buffer; othersise, the changes in the buffer are discarded. T2 is then allowed to read A. This blocking of T2 is similar to the effect of T1 obtaining an exclusive lock on A. Nonetheless, even with this modification, the timestamp protocol permits some schedules not permitted by 2PL; the two protocols are not quite the same.
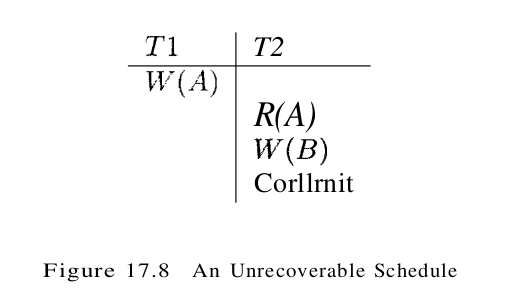
Because recoverability is essential, such a modification must be used for the timestamp protocol to be practical. Given the added overhead this entails, on top of the (considerable) cost of maintaining read and write timestamps, timestamp concurrency control is unlikely to beat lock-based protocols in centralized systems. Indeed, it has been used mainly in the context of distributed database systems.
Multiversion Concurrency Control
This protocol represents yet another way of using timestamps, assigned at startup time, to achieve serializability. The goal is to ensure that a transaction never has to wait to read a database object, and the idea is to maintain several versions of each database object, each with a write timestamp, and let transaction Ti read the most recent version whose timestamp precedes TS(Ti). If transaction Ti wants to write an object, we must ensure that the object has not already been read by some other transaction Tj such that TS(Ti) < TS(Tj). If we allow Ti to write such an object, its change should be seen by Tj for serializability, but obviously Tj, which read the object at Same time in the past, will not see Ti’s change. To check this condition, every object also has an associated read timestamp, and whenever a transaction reads the object, the read timestamp is set to the maximum of the current read timestamp and the reader’s timestamp. If Ti wants to write an object O and TS(Ti) < RTS(O), Ti is aborted and restarted with a new, larger timestamp. Otherwise, Ti creates a new version of O and sets the read and write timestamps of the new version to TS(Ti). The drawbacks of this seheme are similar to those of timestamp concurrency control, and in addition, there is the cost of maintaining versions. On the other hand, reads are never blocked, which can be important for workloads dominated by transactions that only read values from the database.